Materialization policies define the number and types of database artifacts (views or tables) that
are created for intermediate data when you run a DataStage flow in ELT mode. The policy selected
impacts execution performance and intermediate data volume. Execution in ELT mode uses DBT, so ELT
materialization policies overlap with DBT
materializations. Configure settings in your flow's output connector to define target dataset
materialization. When a target dataset gets recreated with table action = replace,
it is materialized as a default DBT materialization table, while table action =
append uses a custom DBT materialization that implements various write modes supported by
DataStage, including insert, update, delete, and more.
Generate nested SQL
Generate nested SQL is the default materialization policy. When selected,
the flow builds separate single SQL statements for each output table. Each statement contains nested
SQL statements for all upstream nodes of the output table. This approach delegates all optimization
work to a database engine.
The Nested Query materialization policy typically avoids creating any
intermediate database artifacts. This simplifies cleanup and avoids leftovers after execution in
case of failure. If an input connector uses a custom SQL statement, then nesting is not possible,
because the relational algebra model cannot be built. In this case, you must select a policy that
generates intermediate views, or the intermediate data is not materialized.
In some cases, flows will have slower performance with this policy. In a flow with multiple
output connectors that share a large number of the same upstream stages, the SQL statements
generated for each of the output connectors will contain the same logic, which will be executed
multiple times by the database. To avoid this repetitive execution, the Advanced policy is
recommended.
Advanced
The Advanced materialization policy creates a single SQL statement for a
set of connected nodes that change data cardinality, or cardinality changers, in order to avoid
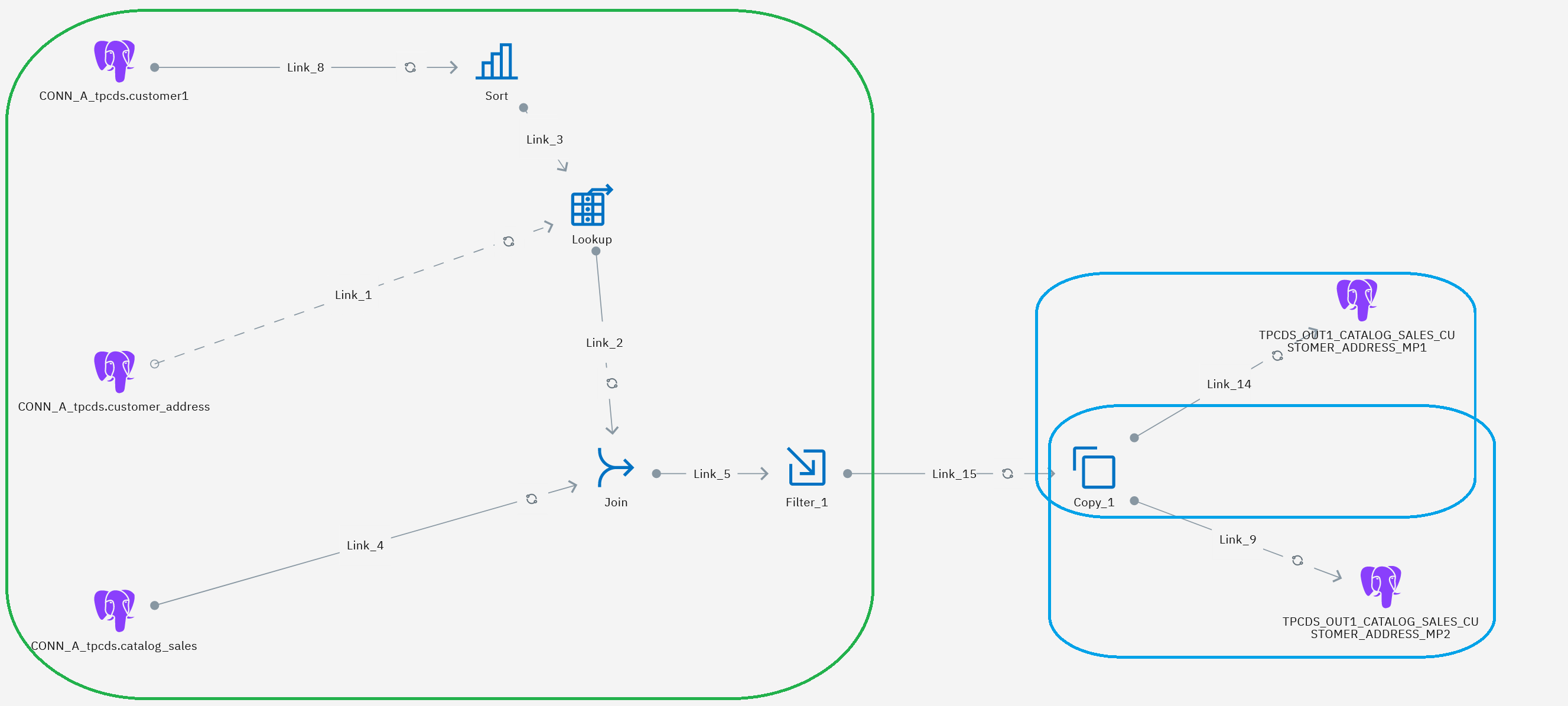
repetitive computations when building output data. The following image shows how these nodes get
combined:Figure 1. Advanced materializion example
The stages defined as cardinality
changers are grouped into a single database artifact. The SQL statement for that artifact includes
the statements for the cardinality changers and their upstream stages. Other stages in the flow use
simple SELECT statements and are not grouped.
This policy performs similarly to Generate nested SQL, but outperforms other policies when
a flow has a high average number of links per stage.
Link as view
All links of a flow are materialized as views and intermediate data is removed after execution.
Link as table
All links of a flow are materialized as tables and intermediate data is removed after execution.
This policy performs similarly to Generate nested SQL because the database engine applies
internal optimization algorithms when it builds output tables. Querying intermediate data has less
performance impact than in Link as view.
Choosing a policy
In cases where flows have multiple output tables to build in parallel, the Advanced policy
may perform better than Generate nested SQL, which does best in most cases. The performance
of these policies also varies based on database engine.
Was the topic helpful?
0/1000
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Cloud Pak for Data relationship map
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.
About cookies on this siteOur websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising.For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.