About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Building ML models in watsonx.ai and batch scoring with Spark in watsonx.data accelerator
Last updated: May 07, 2025
The Building ML models in watsonx.ai and batch scoring with Spark in watsonx.data accelerator guides you through the end-to-end workflow of training and persisting ML models in watsonx.ai and batch scoring those models with Spark at scale in watsonx.data.
Try this accelerator to set up an end-to-end workflow of training and persisting ML models in watsonx.ai and then batch score them at scale with Spark in watsonx.data.
To start, log into the Resource hub and then create a new project that is based on the Building ML models in watsonx.ai and batch scoring with Spark in watsonx.data sample project.
This accelerator provides a scalable ML pattern and implementation that uses a pipeline to automate the end-to-end AI lifecycle, from loading data, training models, selecting the best result to persisting the best model in a model repository. Create and configure the flow once and then run it on demand or on a schedule, without having to interact with individual tools and assets.
The following processes are included:
- Loading training data
- Training a scikit-learn ML model or an AutoAI model on a common training data set
- Comparing the results and selecting the best model. Then persisting the model in model repository
- Transforming the model to a Spark model by using UDF and then performing batch scoring at scale on this model
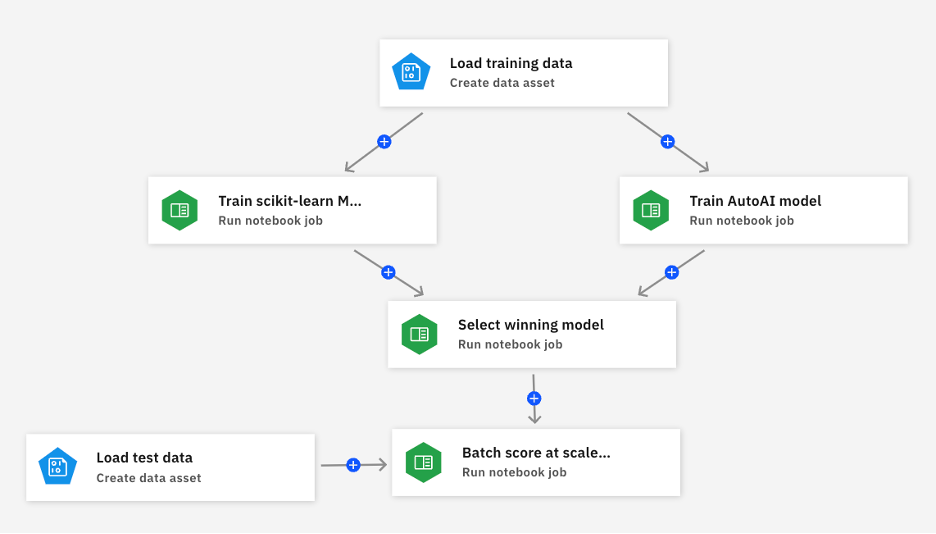
This graph shows a pipeline view of this workflow:
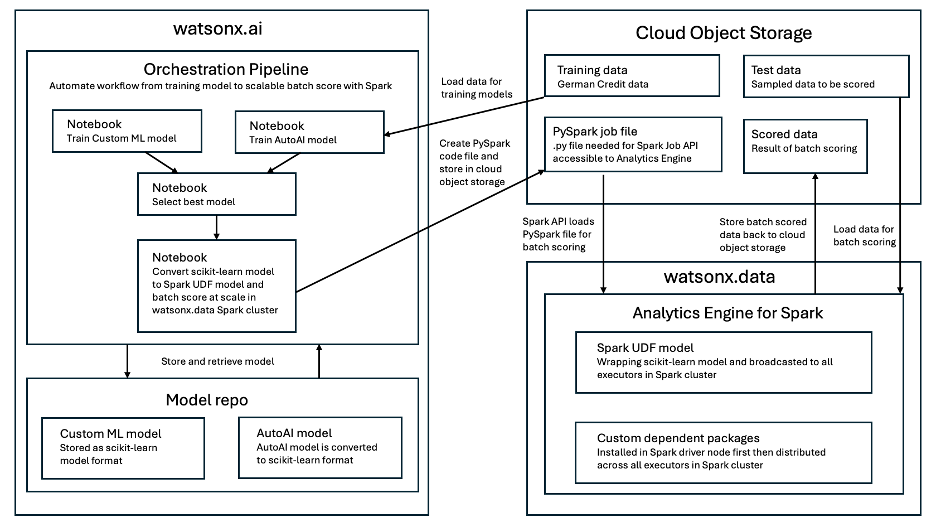
This graph shows a detailed architectural diagram of the scalable ML pattern that is used by the Building ML models in watsonx.ai and batch scoring with Spark in watsonx.data accelerator:
Bring your own model
If you already have a trained model, you can easily customize the workflow to skip the model training steps and load your own data and ML model directly into this watsonx.ai project. Then perform batch scoring with Spark. You can find details of supported model types in the watsonx.ai supported software specification documentation page.
Spark runtime customization
You can customize the Spark engine that is used by watsonx.data to suit your needs. For example, you might want to install third-party libraries for custom analytics, or you might want to fine-tune some of the cluster configurations. You can find more details in the following documentation pages:
Flexible ways to use Spark in watsonx.data
In this pattern, Analytics Engine is used as the Spark engine in watsonx.data, and a notebook that is part of this project shows an example of using Spark API to submit Spark jobs that are written in Python. Other ways to use Spark in watsonx.data exist, too, for example, you can run Spark jobs that are written in R and Scala. See these lists for details:
Various Spark engines
Multiple ways to connect to a Spark runtime in watsonx.data
Parent topic: AI solution accelerators
Was the topic helpful?
0/1000