Data integration tutorial: Virtualize external data
Take this tutorial to virtualize data stored in three external data sources with the Data integration use case of the data fabric trial. Your goal is to use Data Virtualization to create virtual tables and to join the virtual tables together from the existing data that lies across three data sources: a Db2 Warehouse, a PostgreSQL database, and a MongoDB database. If you completed the Integrate data tutorial, then you did many of the same tasks using DataStage that this tutorial accomplishes using Data Virtualization.
The story for the tutorial is that Golden Bank needs to adhere to a new regulation where it cannot lend to underqualified loan applicants. You will use Data Virtualization to combine data from different data sources without data movement, and make the virtual data available to other data scientists and data engineers in a project.
The following animated image provides a quick preview of what you’ll accomplish by the end of this tutorial. You will connect to external data sources, create virtual tables and views, and add them to a project. Click the image to view a larger image.


Preview the tutorial
In this tutorial, you will complete these tasks:
- Set up the prerequisites.
- Task 1: Verify the Platform assets catalog.
- Task 2: Add data connections to the Platform assets catalog.
- Task 3: Add data sources to Data Virtualization.
- Task 4: Virtualize data tables.
- Task 5: Create virtual join views by joining virtual tables.
- Task 6: Generate an API key.
- Task 7: Access the virtual join view in the project.
- Cleanup (Optional)
 Watch this video to preview the steps in this tutorial. There might be slight differences in the user interface shown in the video. The
video is intended to be a companion to the written tutorial.
Watch this video to preview the steps in this tutorial. There might be slight differences in the user interface shown in the video. The
video is intended to be a companion to the written tutorial.
This video provides a visual method to learn the concepts and tasks in this documentation.
Tips for completing this tutorial
Here are some tips for successfully completing this tutorial.
Use the video picture-in-picture
The following animated image shows how to use the video picture-in-picture and table of contents features:

Get help in the community
If you need help with this tutorial, you can ask a question or find an answer in the Cloud Pak for Data Community discussion forum.
Set up your browser windows
For the optimal experience completing this tutorial, open Cloud Pak for Data in one browser window, and keep this tutorial page open in another browser window to switch easily between the two applications. Consider arranging the two browser windows side-by-side to make it easier to follow along.

Set up the prerequisites
Sign up for Cloud Pak for Data as a Service
You must sign up for Cloud Pak for Data as a Service and provision the necessary services for the Data integration use case.
- If you have an existing Cloud Pak for Data as a Service account, then you can get started with this tutorial. If you have a Lite plan account, only one user per account can run this tutorial.
- If you don't have an account yet, then sign up for a data fabric trial.
![]() Watch the following video to learn about data fabric in Cloud Pak for Data.
Watch the following video to learn about data fabric in Cloud Pak for Data.
This video provides a visual method to learn the concepts and tasks in this documentation.
Verify the necessary provisioned services
To preview this task, watch the video beginning at 01:06.
Follow these steps to verify or provision the necessary services:
-
From the Navigation menu
 , choose Services > Service instances.
, choose Services > Service instances. -
Use the Product drop-down list to determine whether an existing Data Virtualization service instance exists.
-
If you need to create a Data Virtualization service instance, click Add service.
-
Select Data Virtualization.
-
Select the Lite plan.
-
Click Create.
-
-
Wait while the Data Virtualization service is provisioned, which might take a few minutes to complete.
-
Repeat these steps to verify or provision the following additional services:
- IBM Knowledge Catalog
- Cloud Object Storage
 Check your progress
Check your progress
The following image shows the provisioned service instances:
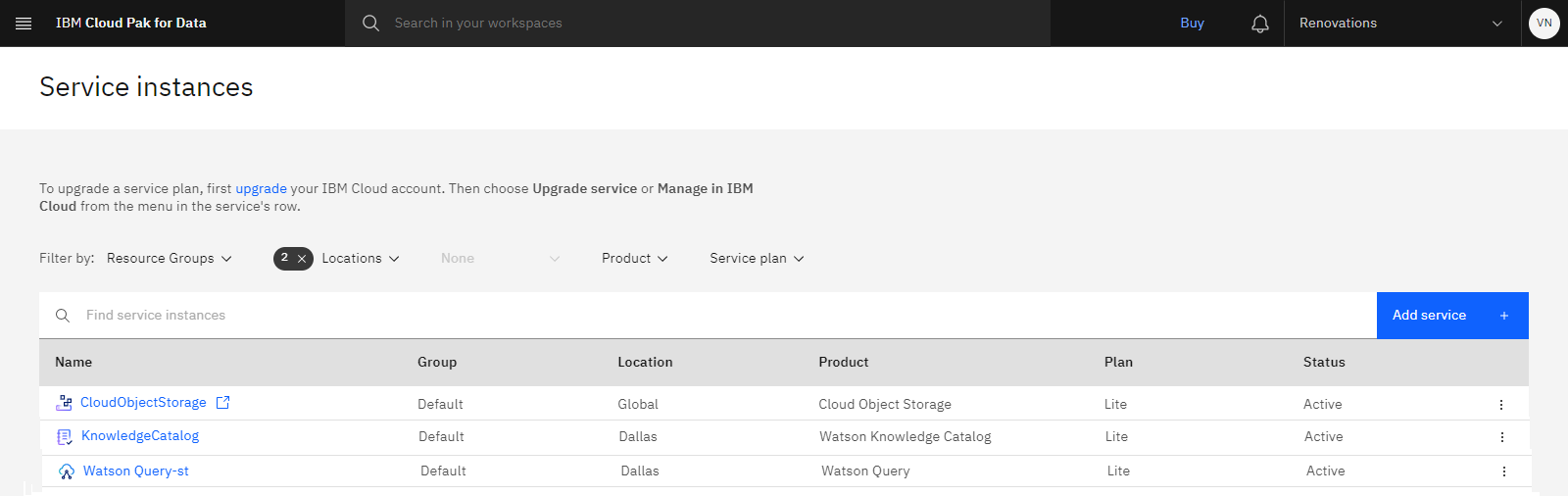
Create the sample project
To preview this task, watch the video beginning at 01:46.
If you already have the sample project for this tutorial, then skip to Task 1. Otherwise, follow these steps:
-
Access the Data integration sample project in the Resource hub.
-
Click Create project.
-
If prompted to associate the project to a Cloud Object Storage instance, select a Cloud Object Storage instance from the list.
-
Click Create.
-
Wait for the project import to complete, and then click View new project to verify that the project and assets were created successfully.
-
Click the Assets tab to see the connections and DataStage flow.
Check your progress
The following image shows the Assets tab in the sample project. You are now ready to start the tutorial.
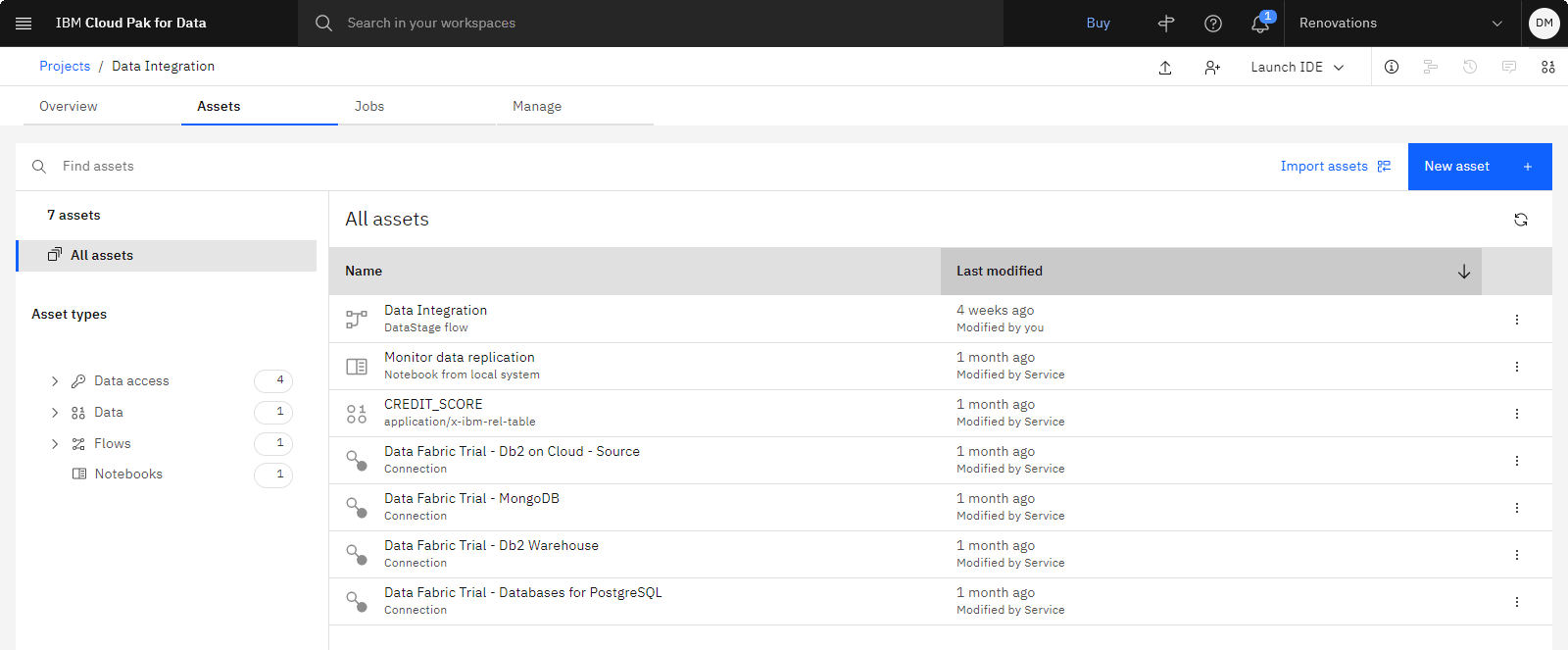
Task 1: Verify the Platform assets catalog
To preview this task, watch the video beginning at 02:42.
You can add connections to external data sources at either the platform level or the service level. When you add the connections at the platform level by using the Platform assets catalog, you can easily include those connections in projects, catalogs, and Data Virtualization data sources. Follow these steps to verify the Platform assets catalog.
-
From the Navigation menu
, choose Data > Platform connections. -
If you see existing connections, then you already have a Platform assets catalog, and you can skip to Task 2. If you don't see any connections, but you see an option to create a new connection, then you can skip to Task 2.

-
If you don't have a Platform assets catalog, click Create catalog.

-
Select a Cloud Object Storage from the list.
-
Accept the default value for Duplicate asset handling.
-
Click Create. The Platform connections page displays.
Check your progress
The following image shows the platform connections. From here, you can create connections. Since the sample project includes the connections, you can add the connections for the external data sources to this catalog from the sample project.
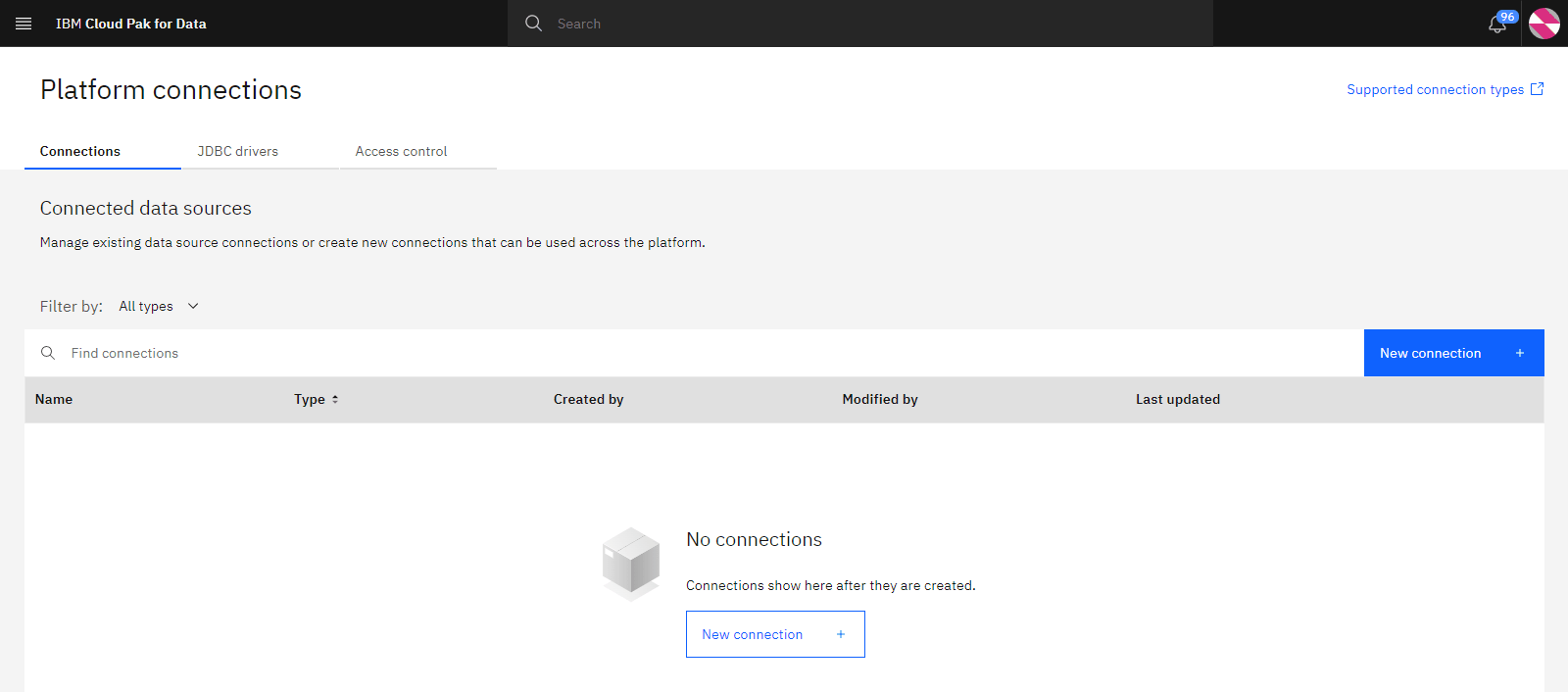
Task 2: Add data connections to the Platform assets catalog
To preview this task, watch the video beginning at 03:22.
The Data integration sample project includes several connections to external data sources. Next, you add three connections to the Platform assets catalog, and then you can make these connections available in Data Virtualization. Follow these steps to publish the connections from the sample project to the Platform assets catalog.
-
From the Navigation menu
, choose Projects > View all projects. -
Click the Data integration project.
-
Click the Assets tab.
-
Under Asset types, click Data access > Connections.
-
Select the following connection assets:
- Data Fabric Trial - Db2 Warehouse
- Data Fabric Trial - MongoDB
- Data Fabric Trial - Databases for PostgreSQL
-
Click Publish to catalog.
-
Select the Platform Assets Catalog from the list, and click Next.
-
Review the assets, and click Publish.
-
-
From the Navigation menu
, choose Data > Platform connections to
see the three connections that are published to the catalog.
Check your progress
The following image shows the three platform connections. You are now ready to add data sources.
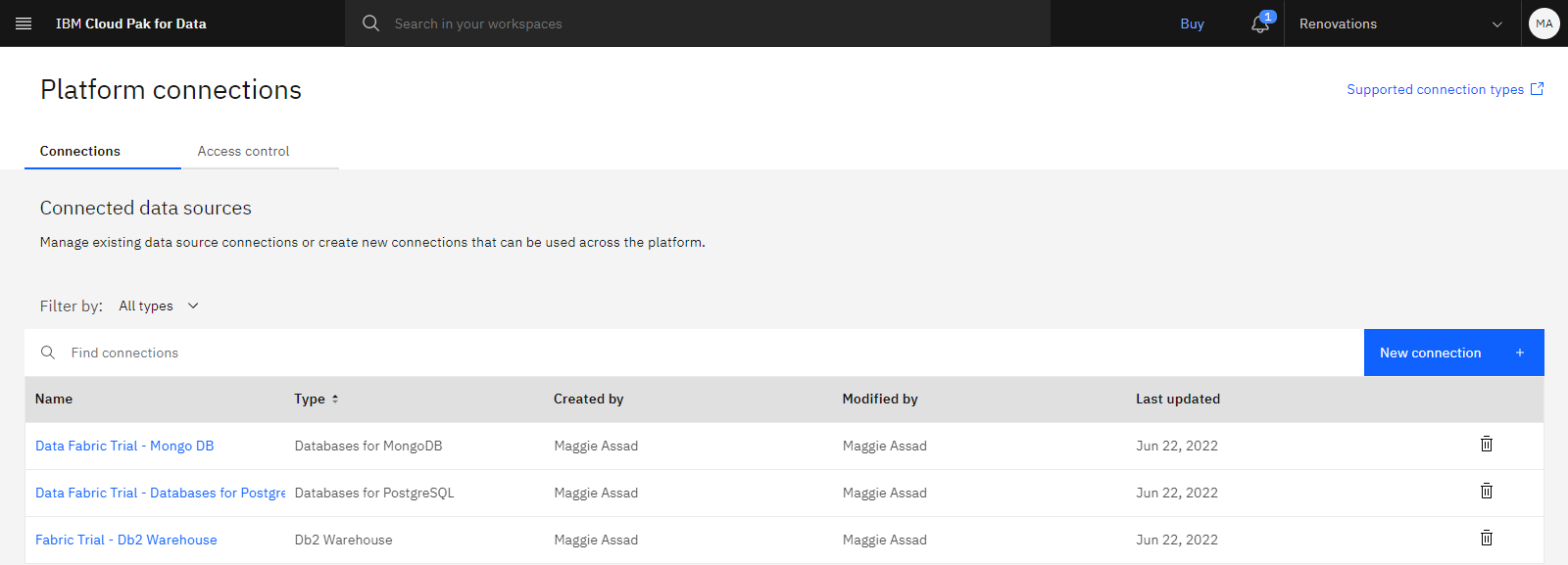
Task 3: Add data sources to Data Virtualization
To preview this task, watch the video beginning at 04:05.
Now you can add these external data sources from the Platform assets catalog to Data Virtualization. Follow these steps to add the data sources:
-
From the Navigation menu
, choose Data > Data virtualization.Note: If you see a notification to Set up a primary catalog to enforce governance, you can safely close this notification. Setting up a primary catalog is optional. -
On the Data sources page, in the Table view, click Add connection > Existing platform connection.

-
Select Data Fabric Trial - Db2 Warehouse.
-
Click Add.
-
Repeat these steps to add the Data Fabric Trial - Mongo DB and Data Fabric Trial - Databases for PostgreSQL connections.
Check your progress
The following image shows the data sources. You are now ready to create a virtual table from data stored in those external data sources.
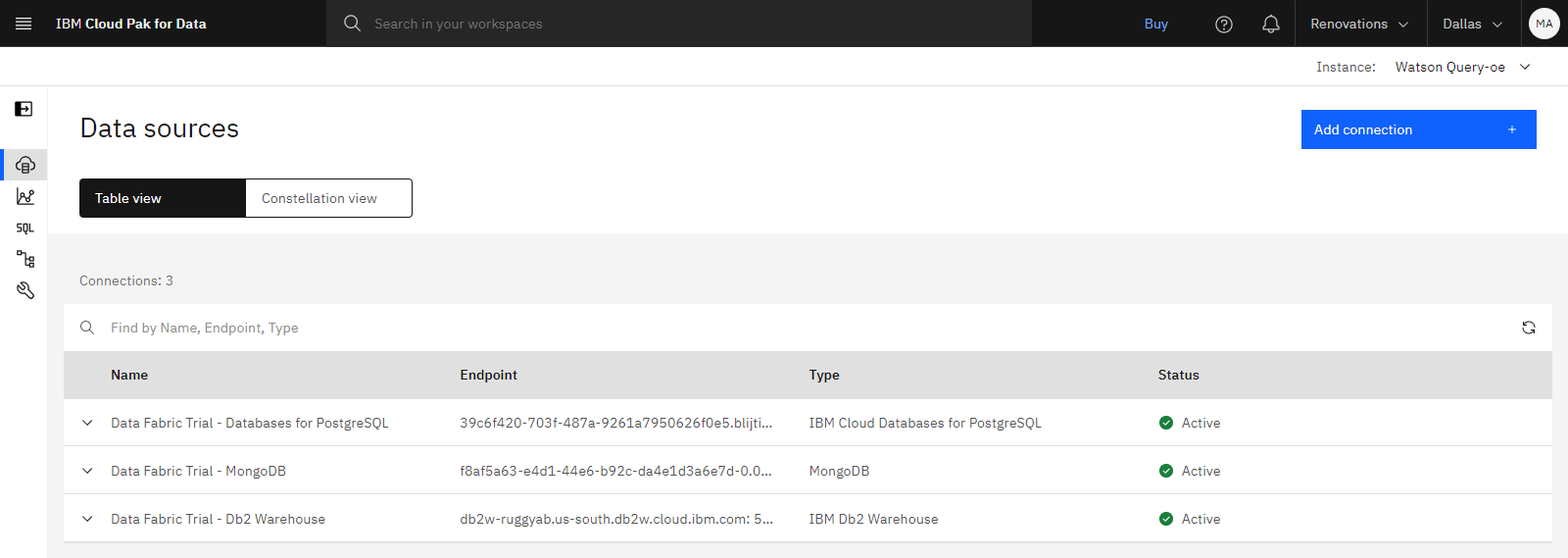
Task 4: Virtualize data tables
To preview this task, watch the video beginning at 04:40.
You want to virtualize the MORTGAGE_APPLICATION, MORTGAGE_APPLICANT, and CREDIT_SCORES tables. Later, you can join the first two virtual tables with the third table to create a new virtual join view. Follow these steps to virtualize the data tables:
-
From the service menu, click Virtualization > Virtualize.

-
If necessary, change to Tables view, and wait while the tables load, which might take up to 30 seconds. You may need to click Refresh to see the complete list of tables. When you see Available tables, then all of the tables loaded. The number of tables may vary.

-
On the Tables tab, filter the tables based on the following criteria:
-
Connector: IBM Db2 Warehouse and PostgreSQL
-
Database: Data Fabric Trial - Db2 Warehouse and Data Fabric Trial - Databases for PostgreSQL
-
Schema: BANKING
-
-
Select the MORTGAGE_APPLICATION, MORTGAGE_APPLICANT, and CREDIT_SCORE tables to virtualize. You can hover over a table name to see the full name to verify that you are selecting the correct table names.
-
Click Add to cart.
-
Click View cart to view your selection. From here, you can edit the table and schema names, or remove a selection from your cart.
-
For now, clear the checkbox next to Assign to project. This action will make the virtual tables available on the Virtualized data page.
-
Click Virtualize.
-
Click Confirm to begin virtualizing the tables.
-
When virtualization is complete, click Go to virtualized data to see your newly created table.
Check your progress
The following image shows the Virtualized data page. You are now ready to create a virtual table by joining these virtual tables.
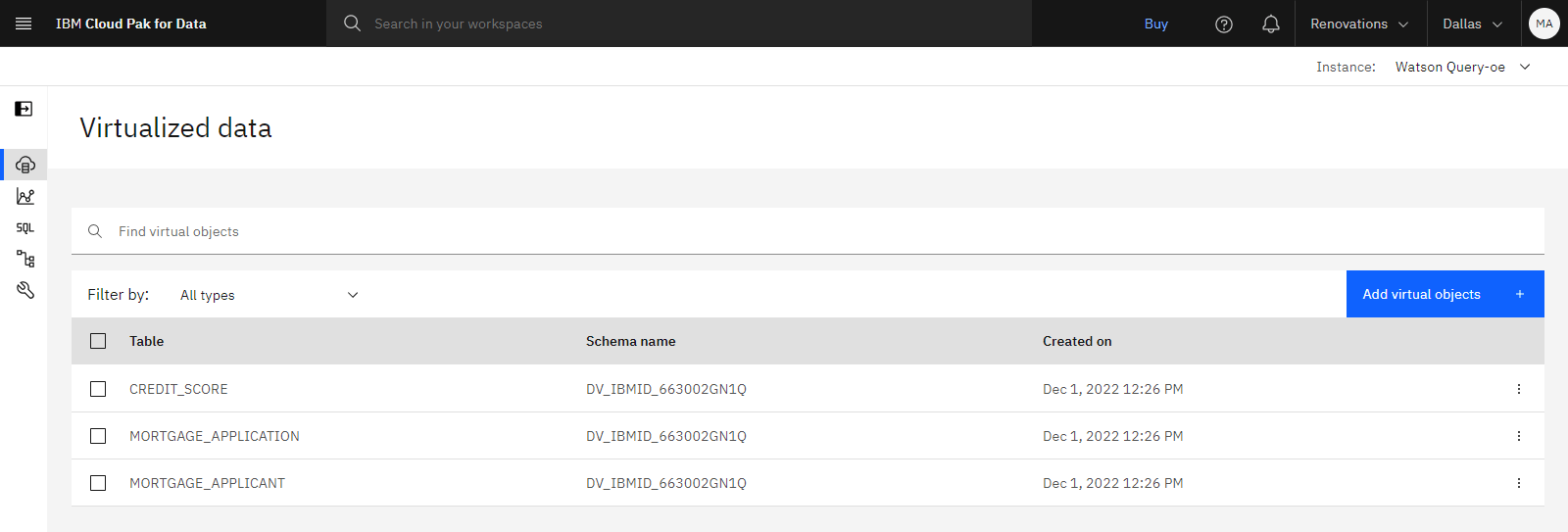
Task 5: Create virtual join views by joining virtual tables
You want to create a virtual join view by joining the MORTGAGE_APPLICANT and MORTGAGE_APPLICATION virtual tables. Then, you want to join the resulting virtual object with the CREDIT_SCORE virtual table to create a second virtual join view.
Virtual join view 1: Join the MORTGAGE_APPLICANT and MORTGAGE_APPLICATION virtual tables
To preview this task, watch the video beginning at 05:59.
Follow these steps to create the first virtual join view:
-
From the Virtualized data page, select the MORTGAGE_APPLICATION and MORTGAGE_APPLICANT tables to virtualize.
-
Make note of the schema name. You will need that name later to run an SQL query.
-
Click Join.
-
In the list of columns for MORTGAGE_APPLICATION table, drag to connect the ID column with the ID column in the MORTGAGE_APPLICANT table.

-
Select all columns in both tables.
-
Click Preview to see a preview of the joined tables.
-
Close the preview window.
-
Click Open in SQL editor, and then click Continue at the notice that you are not able to return to the join canvas. The SQL Editor lets you run queries on the data set. In this case, you want to preview what records the data set will contain when you filter on California applicants.

-
Copy your schema, and then delete the existing query. You will need to insert your schema in the next SQL statement.
-
Copy and paste the following SELECT statement for the new query. Replace
<your schema>with the schema name that you noted earlier.SELECT * FROM <your-schema>.MORTGAGE_APPLICANT WHERE STATE_CODE LIKE 'CA'Your query looks similar to SELECT * FROM DV_IBMID_663002GN1Q.MORTGAGE_APPLICANT WHERE STATE_CODE LIKE 'CA'

-
Click Run all.
-
After the query completes, select the query on the History tab. On the Results tab, you can see that the table is filtered to only applicants from the state of California.
-
Click Back to close the SQL editor.
-
-
Now that you previewed the data set filtered on California applicants, you will add this filter criteria to the virtual join view. For the MORTGAGE_APPLICANT table, copy and paste the following statement for the filter criteria. Replace
<your schema>with the schema name that you noted earlier."<your-schema>"."MORTGAGE_APPLICANT"."STATE_CODE"='CA'Your filter criteria looks similar to "DV_IBMID_663002GN1Q"."MORTGAGE_APPLICANT"."STATE_CODE"='CA'

-
Click Next.
-
You can edit the column names to differentiate between columns with the same name in both tables. In this case, keep the default column names, and click Next.
-
On the Assign and review page, for the View name, type
APPLICANTS_APPLICATIONS_JOINED. -
For now, clear the Assign to project option. Later, you create a virtual object and assign that to the Data integration project.
-
Click Create view.
-
When virtualization is complete, click Go to virtualized data to see your newly created join view.
Check your progress
The following image shows the Virtualized data page. You are now ready to create a second virtual join view.
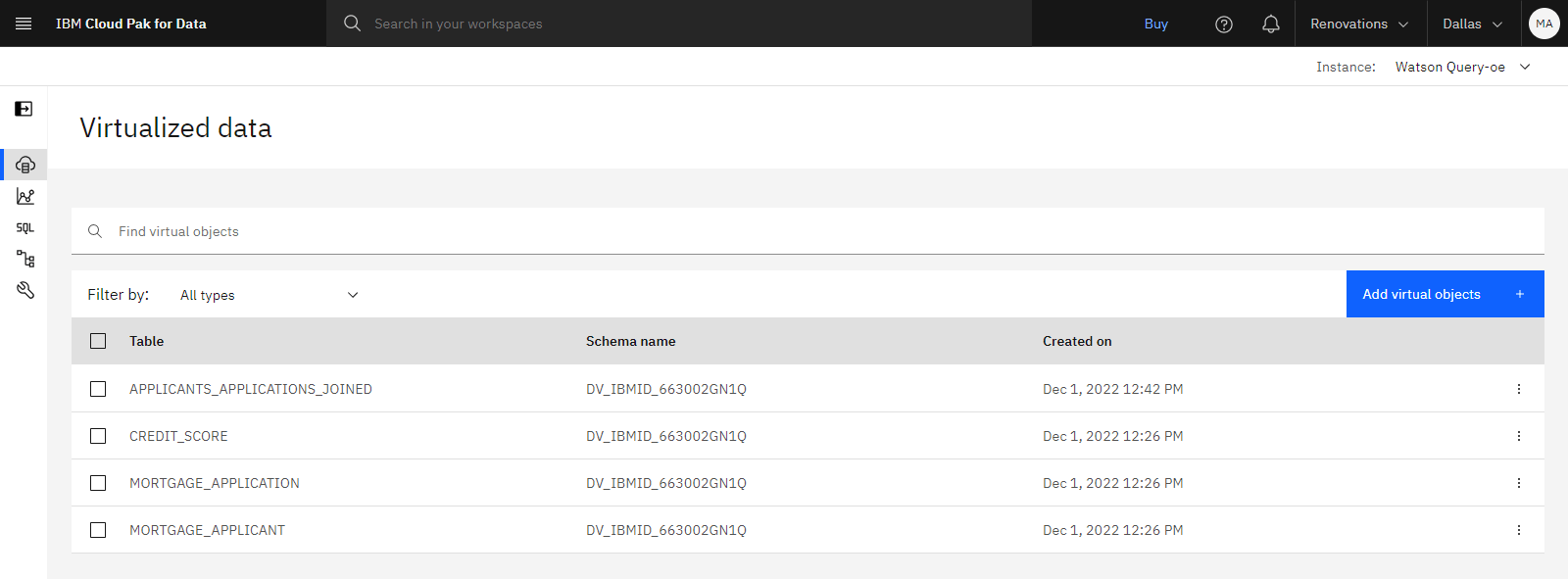
Virtual join view 2: Join the APPLICANTS_APPLICATIONS_JOINED and CREDIT_SCORE virtual tables
To preview this task, watch the video beginning at 07:47.
Follow these steps to create the second virtual join view:
-
From the Virtualized data page, select the APPLICANTS_APPLICATIONS_JOINED and CREDIT_SCORE tables to virtualize.
-
Click Join.
-
In the list of columns for APPLICANTS_APPLICATIONS_JOINED table, drag to connect the EMAIL_ADDRESS column with the EMAIL_ADDRESS column in the CREDIT_SCORE table.
-
Click Preview to see a preview of the joined tables.
-
Close the preview window.
-
Click Next.
-
Accept the default column names, and click Next.
-
On the Assign and review page, for the View name, type
APPLICANTS_APPLICATIONS_CREDIT_SCORE_JOINED. -
This time, keep Assign to project selected, and then choose the Data integration project.
-
Click Create view.
-
When virtualization is complete, click Go to virtualized data to see your newly created join view.
Check your progress
The following image shows the Virtualized data page. You are now ready to work with the virtual data in your project.
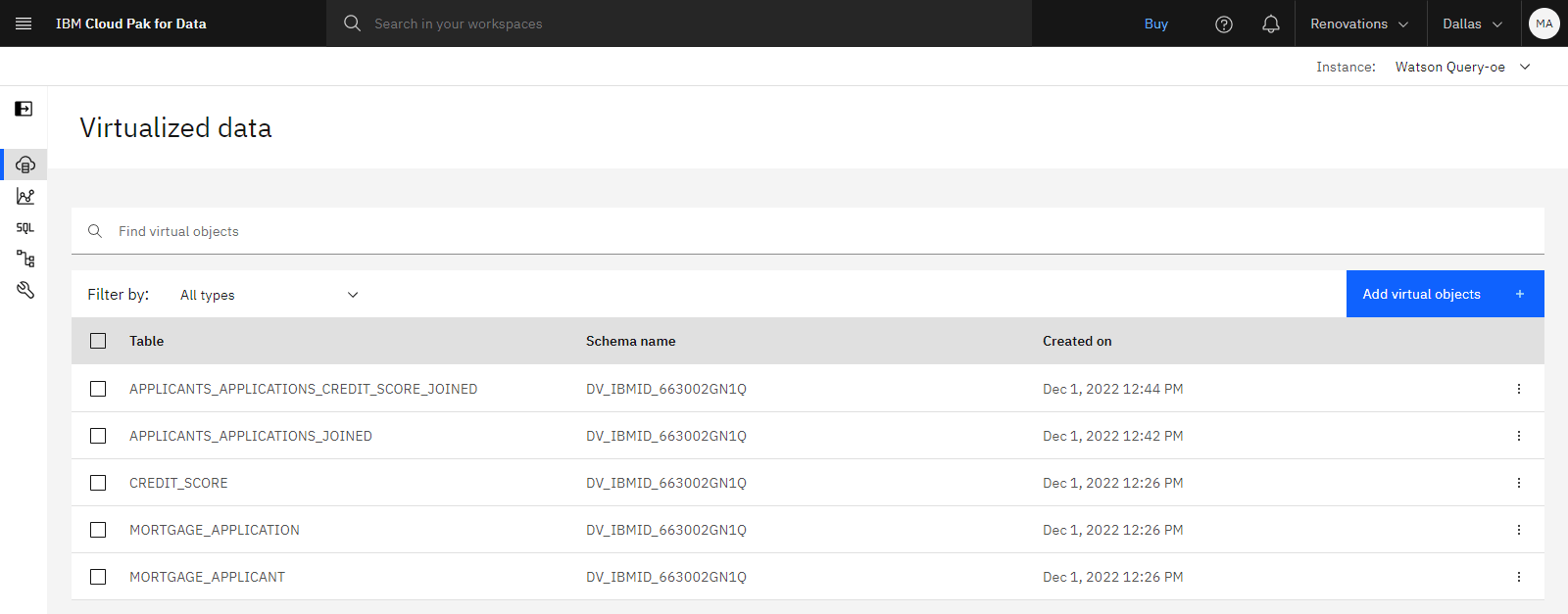
Task 6: Generate an API key
To preview this task, watch the video beginning at 08:27.
You need to provide your personal credentials in the form of an API key to view virtualized assets. If you don't already have a saved API key, then follow these steps to create an API key.
-
Access the API keys page in the IBM Cloud console. Log in if prompted.
-
On the API keys page, click Create an IBM Cloud API key. If you have any existing API keys, the button may be labelled Create.
-
Type a name and description.
-
Click Create.
-
Copy the API key.
-
Download the API key for future use.
Check your progress
The following image shows the API keys page. You are now ready to view the virtual table in the project.
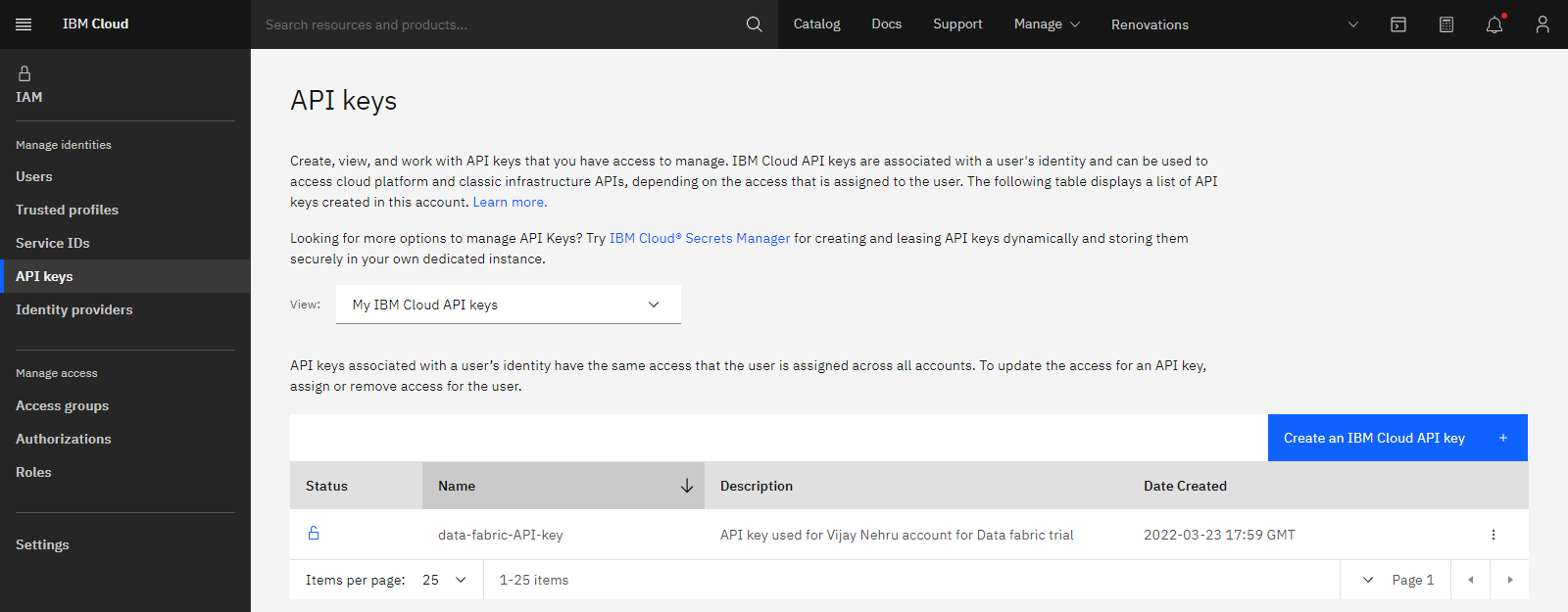
Task 7: Access the virtual join view in the project
To preview this task, watch the video beginning at 09:01.
The virtual table was added to your project along with a connection to Data Virtualization. Follow these steps to open the project to see the virtual data and the connection information that is required to access the virtual data.
-
Switch back to Cloud Pak for Data. From the Navigation Menu
, choose Projects > View all projects. -
Open the Data integration project.
-
Click the Assets tab.
-
Open any of the virtualized data. For example, click the data asset beginning with your schema name followed by APPLICANTS_APPLICATIONS_CREDIT_SCORE_JOINED to view it.
-
Provide your credentials to access the data asset.
-
For the Authentication method, select API Key.
-
Paste your API key.

-
Click Connect.
-
Scroll through the data asset to see all of the applicants from the state of California.
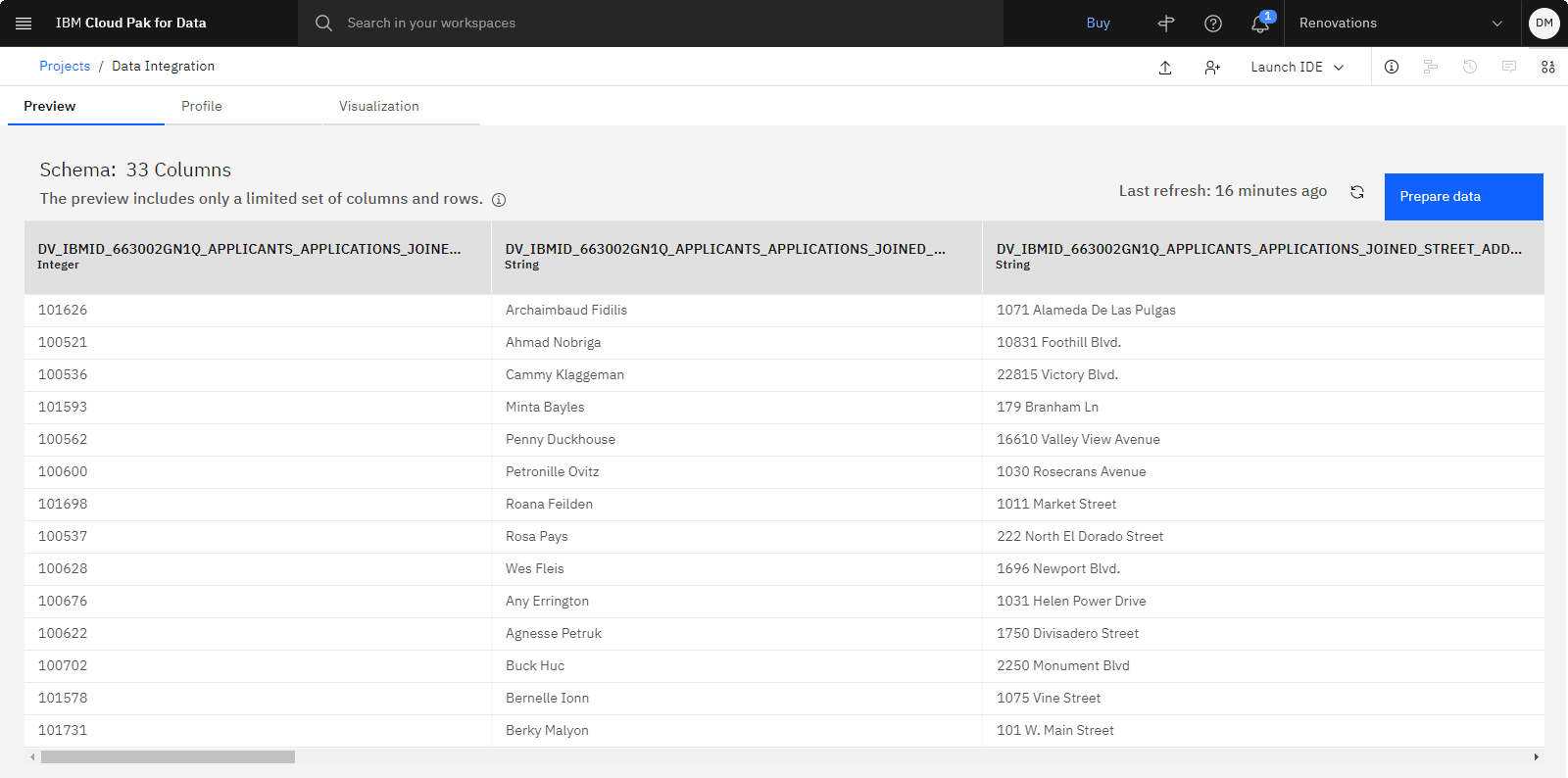
Check your progress
The following image shows the virtual data in the project. You are now ready to analyze the virtual data.
As a data engineer at Golden Bank, you used Data Virtualization to combine data from different data sources and with different types. You used SQL syntax and accessed and combined data without data movement.
Cleanup (Optional)
If you would like to retake the tutorials in the Data integration use case, delete the following artifacts.
| Artifact | How to delete |
|---|---|
| Connections in the Platform assets catalog | Remove an asset from a catalog |
| Virtualized data | Navigate to Data > Data virtualization; On the Virtualized data page, access the Overflow menu |
| Data sources | Navigate to Data > Data virtualization; On the Data sources page, click the Delete icon |
| Data integration sample project | Delete a project |
Next steps
Learn more
Parent topic: Use case tutorials