About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Quick start: Use DataStage to load enterprise data into Snowflake
Last updated: Jul 04, 2025
DataStage is a modernized data integration tool that helps users build trusted data pipelines, orchestrate data across distributed landscapes, and move and transform data between cloud sources and data warehouses. It provides a Snowflake connector, among many others, to write, read, and load data into Snowflake and integrate it into the ETL job design. This quick start tutorial demonstrates how to load enterprise data into Snowflake quickly and efficiently through DataStage.
- Required services
- DataStage
In this tutorial, you will complete these tasks:
- Task 1: Create a Snowflake data warehouse.
- Task 2: Create the sample project and provision the DataStage service.
- Task 3: Create a connection to your Snowflake data warehouse.
- Task 4: Create a DataStage flow.
- Task 5: Design DataStage flow.
- Task 6: Run the DataStage flow.
- Task 7: View the data asset in the Snowflake data warehouse.
This tutorial takes approximately 20 minutes to complete.
Preview the tutorial
 Watch this video to see how to create a simple DataStage flow.
Watch this video to see how to create a simple DataStage flow.
This video provides a visual method to learn the concepts and tasks in this documentation.
Tips for completing this tutorial
Here are some tips for successfully completing this tutorial.
Use the video picture-in-picture
Tip: Start the video, then as you scroll through the tutorial, the video moves to picture-in-picture mode. Close the video table of contents for the best experience with picture-in-picture. You can use picture-in-picture
mode so you can follow the video as you complete the tasks in this tutorial. Click the timestamps for each task to follow along.
The following animated image shows how to use the video picture-in-picture and table of contents features:

Get help in the community
If you need help with this tutorial, you can ask a question or find an answer in the Cloud Pak for Data Community discussion forum.
Set up your browser windows
For the optimal experience completing this tutorial, open Cloud Pak for Data in one browser window, and keep this tutorial page open in another browser window to switch easily between the two applications. Consider arranging the two browser windows side-by-side to make it easier to follow along.

Tip: If you encounter a guided tour while completing this tutorial in the user interface, click Maybe later.
Set up the prerequisites
Sign up for a Snowflake trial account
To preview this task, watch the video beginning at 00:05.
-
Go to https://www.snowflake.com/.
-
Click START FOR FREE.
-
Complete the signup form, and click Continue.
-
On the START YOUR 30-DAY FREE TRIAL page, complete these steps:
-
Choose a Snowflake edition.
-
Choose a cloud provider.
-
Click GET STARTED.
-
-
Skip the questions until you see the Thanks for signing up with Snowflake message.
-
Access your email account, open the email from Snowflake Computing, and click CLICK TO ACTIVATE.
-
Provide a username and password, and click Get started.
 Check your progress
Check your progress
The following image shows the Snowflake dashboard:
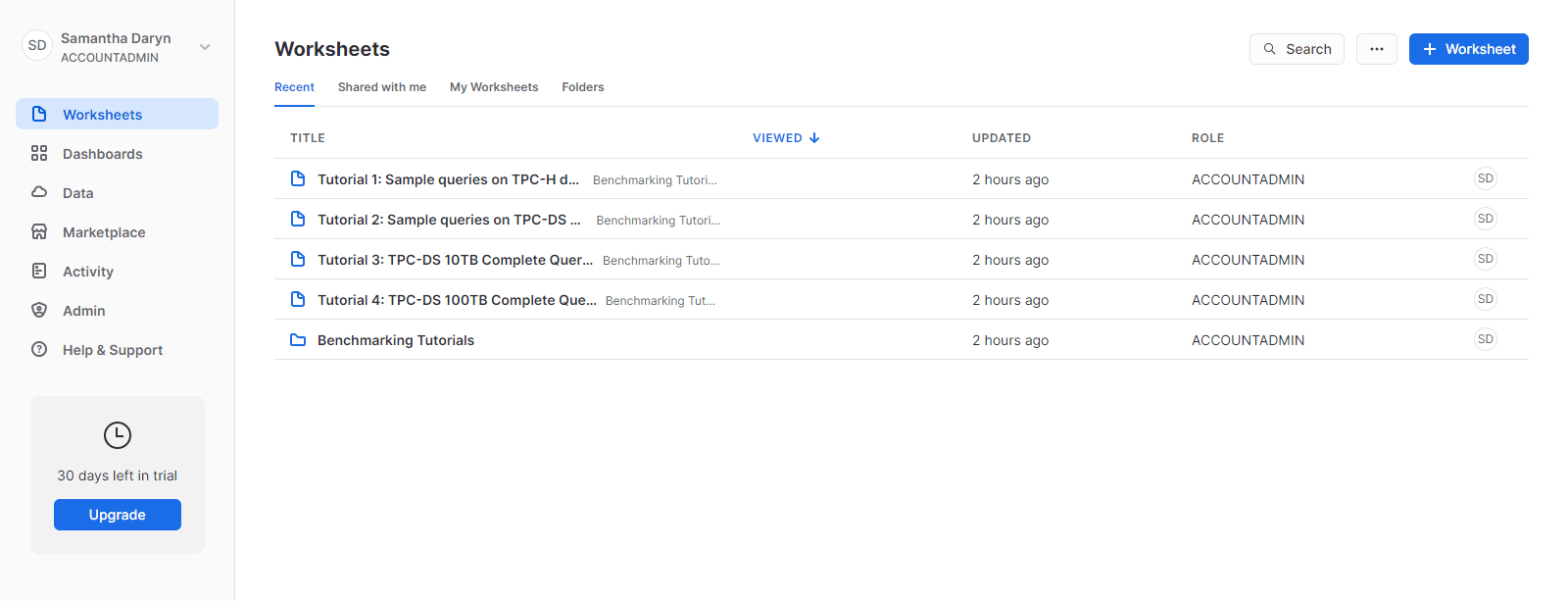
Sign up for the DataStage trial on Cloud Pak for Data as a Service
To preview this task, watch the video beginning at 00:36.
You must sign up for Cloud Pak for Data as a Service and provision the DataStage service. Go to the DataStage trial page. Using this link, the following services are provisioned:
- DataStage
- Cloud Object Storage
With existing IBMid
If you have an existing IBMid, watch this short video.
This video provides a visual method to learn the concepts and tasks in this documentation.
With new IBMid
If you don't have an existing IBMid, watch this short video.
This video provides a visual method to learn the concepts and tasks in this documentation.
Check your progress
The following image shows the Cloud Pak for Data home page:
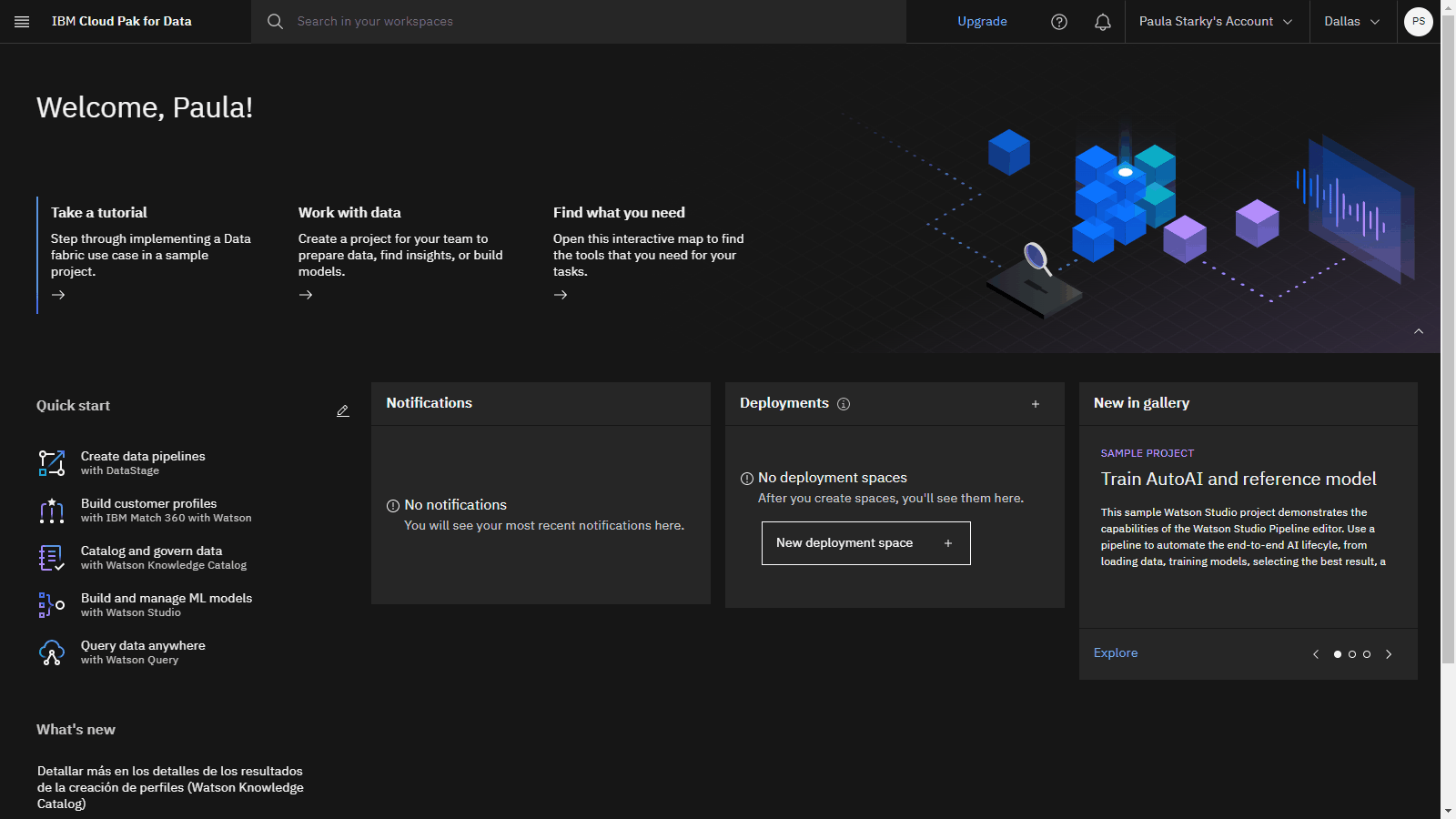
For more information on provisioning services, see Creating and managing IBM Cloud services.
Check your progress
The following image shows the required provisioned service instances. You are now ready to sign up for the Snowflake trial.
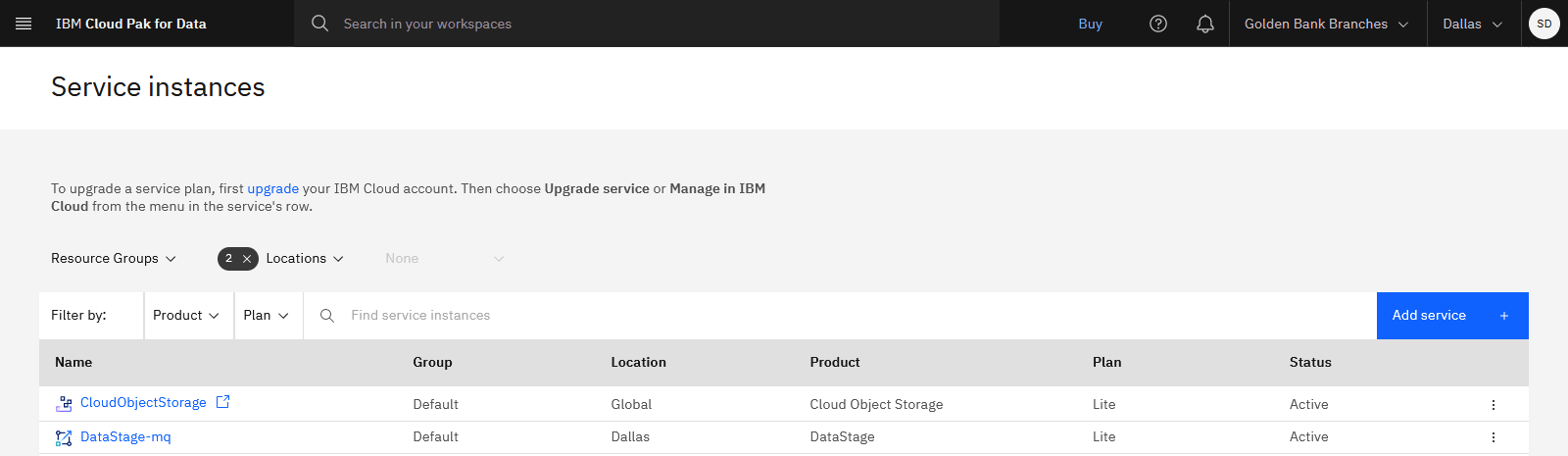
Task 1: Create a Snowflake data warehouse
To preview this task, watch the video beginning at 00:51.
Your goal is to use DataStage to load data into your Snowflake account. To accomplish that, you need a data warehouse in your Snowflake account. Follow these steps to create a data warehouse in your Snowflake account:
-
Log in to your Snowflake trial account.
-
In the navigation panel, click Admin > Warehouses.
-
Click + Warehouse.
-
For the Name, type:
-
Accept the defaults for the rest of the fields, and click Create Warehouse.
-
-
In the navigation panel, click Data.
-
On the Databases page, click + Database.
-
For the Name, type
, and click Create.
-
-
Click the newly created DATASTAGEDB database in the list, and click + Schema.
-
For the Schema name, type:
-
Click Create.
-
-
In the list of databases, select DATASTAGEDB > MORTGAGE.
Check your progress
The following image shows the DATASTAGEDB database in Snowflake. You are now ready to create the sample project in Cloud Pak for Data for the connection information and the DataStage flow.
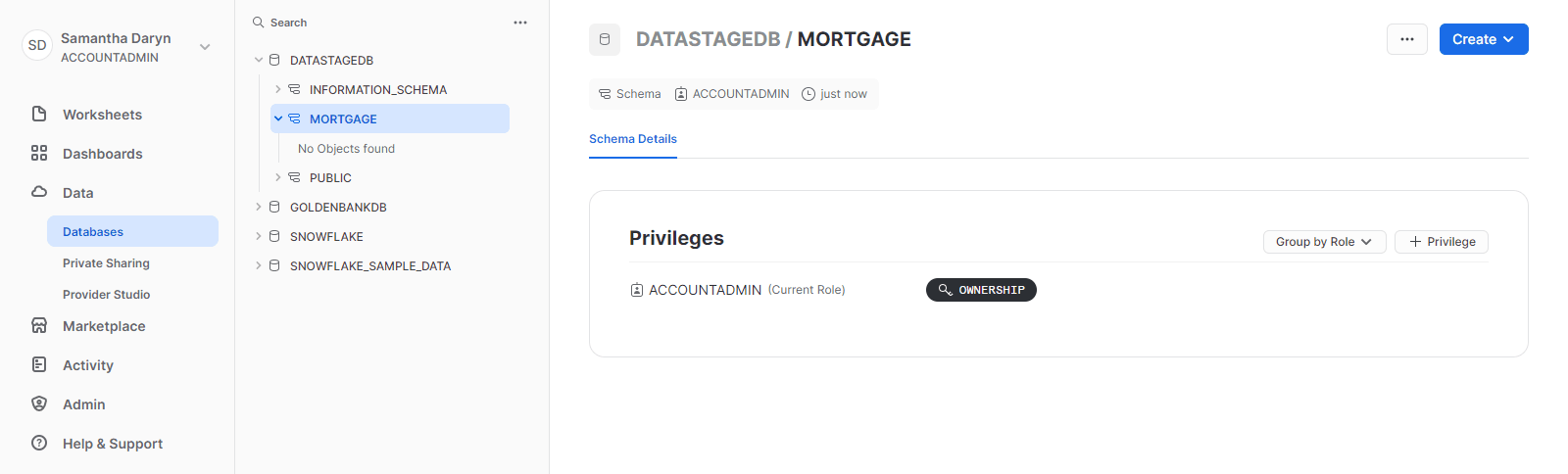
Task 2: Create the DataStage project
To preview this task, watch the video beginning at 01:46.
You need a project to store the connections to the external data sources and the DataStage flow. Follow these steps to create the sample project:
-
Access the Data integration sample project in the Resource hub.
-
Click Create project.
-
If prompted to associate the project to a Cloud Object Storage instance, select a Cloud Object Storage instance from the list.
-
Click Create.
-
Wait for the project import to complete, and then click View new project.
-
Click the Assets tab to verify that the project and assets were created successfully.
Check your progress
The following image shows the sample project. Now you are ready to create the connection to Snowflake.
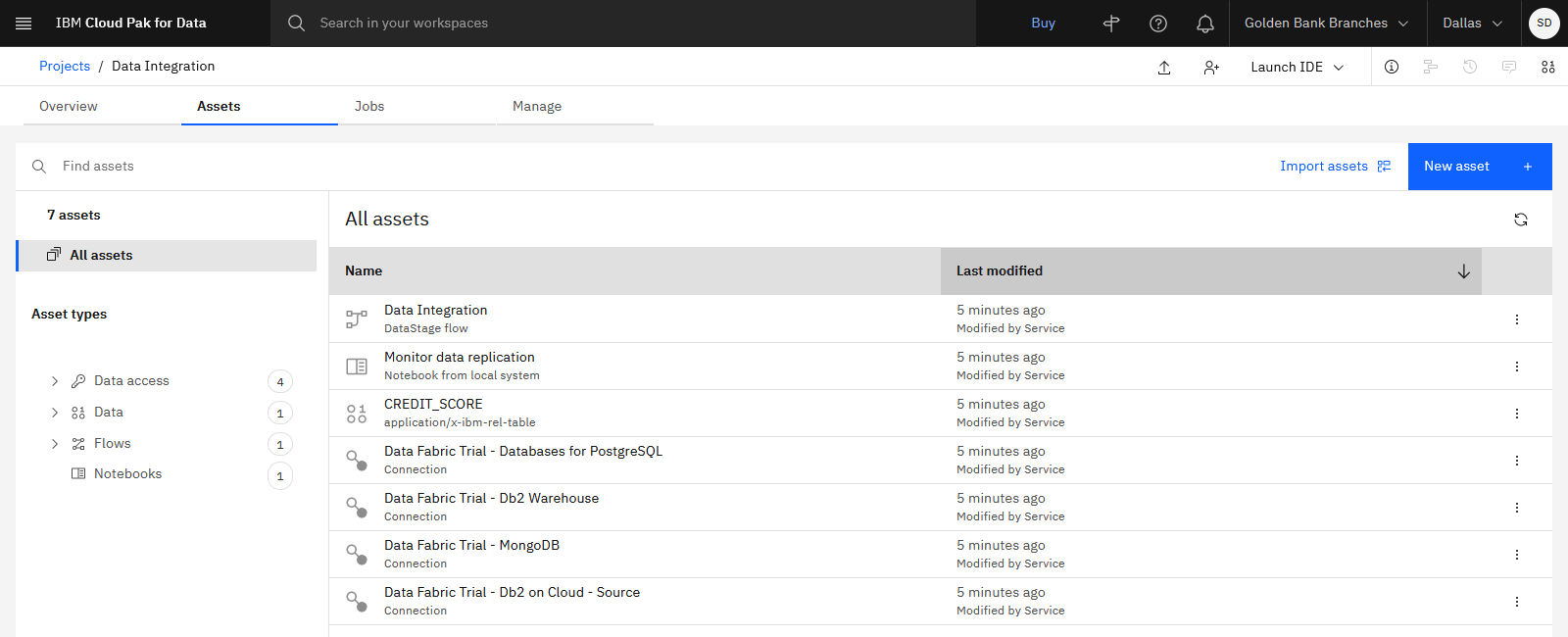
Task 3: Create a connection to your Snowflake data warehouse
To preview this task, watch the video beginning at 02:17.
You need to add the connection information to your project so you can access the Snowflake data warehouse in your DataStage flow. Follow these steps to create a connection asset in your project:
-
On the Assets tab, click New asset > Connect to a data source.
-
Search for Snowflake in the Find connectors search field.
-
Select the Snowflake connection type, and click Next.
-
On the Create connection: Snowflake page, type
for the connection name. -
For the Connection details, complete the following fields by using the information from the Snowflake account that you just created:
-
Account name: Your account name is a combination of your account ID, your region, and your cloud provider. You can find this information in the URL when logged in to your Snowflake account.
-
Click your username to see the menu options.
-
Hover over your Account.
-
In the account menu, hover over your account link.
-
Click the Copy account URL icon as seen in the following image:
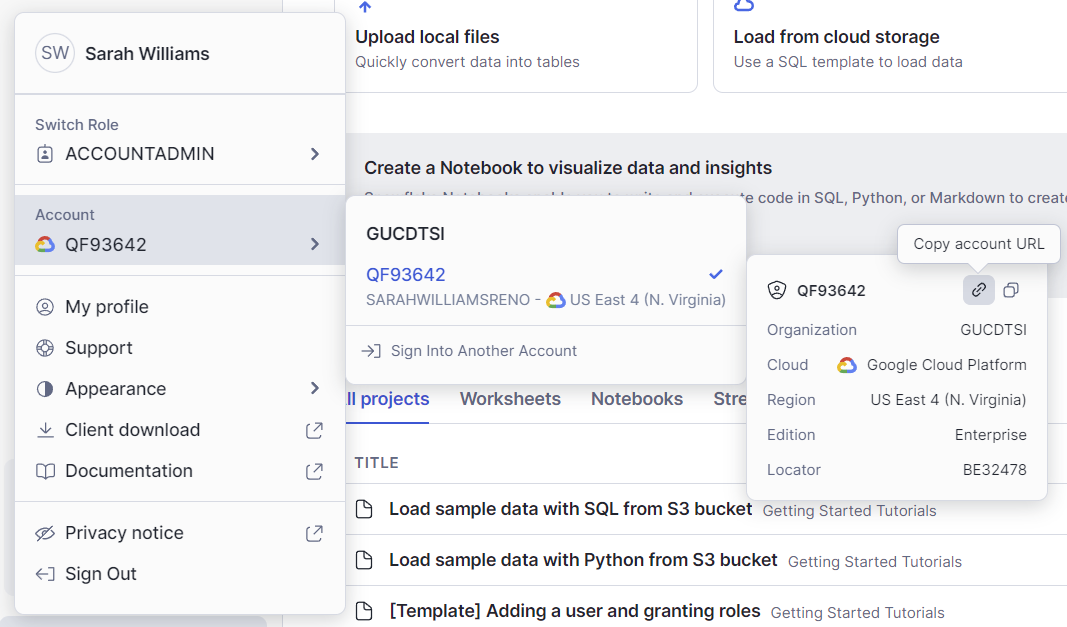
-
-
Database: Type
-
Role: Type
-
Warehouse: Type
-
Username: Type your Snowflake account username.
-
Password: Type your Snowflake account password.
-
-
Click Test Connection to test the connection to your Snowflake account.
-
If the test is successful, click Create. If prompted to create the connection without setting location and sovereignty, click Create. This action creates the Snowflake connector, which you can use to load the data from Db2 Warehouse into your Snowflake account.
Check your progress
The following image shows the new connection information. Now you are ready to create the DataStage flow.
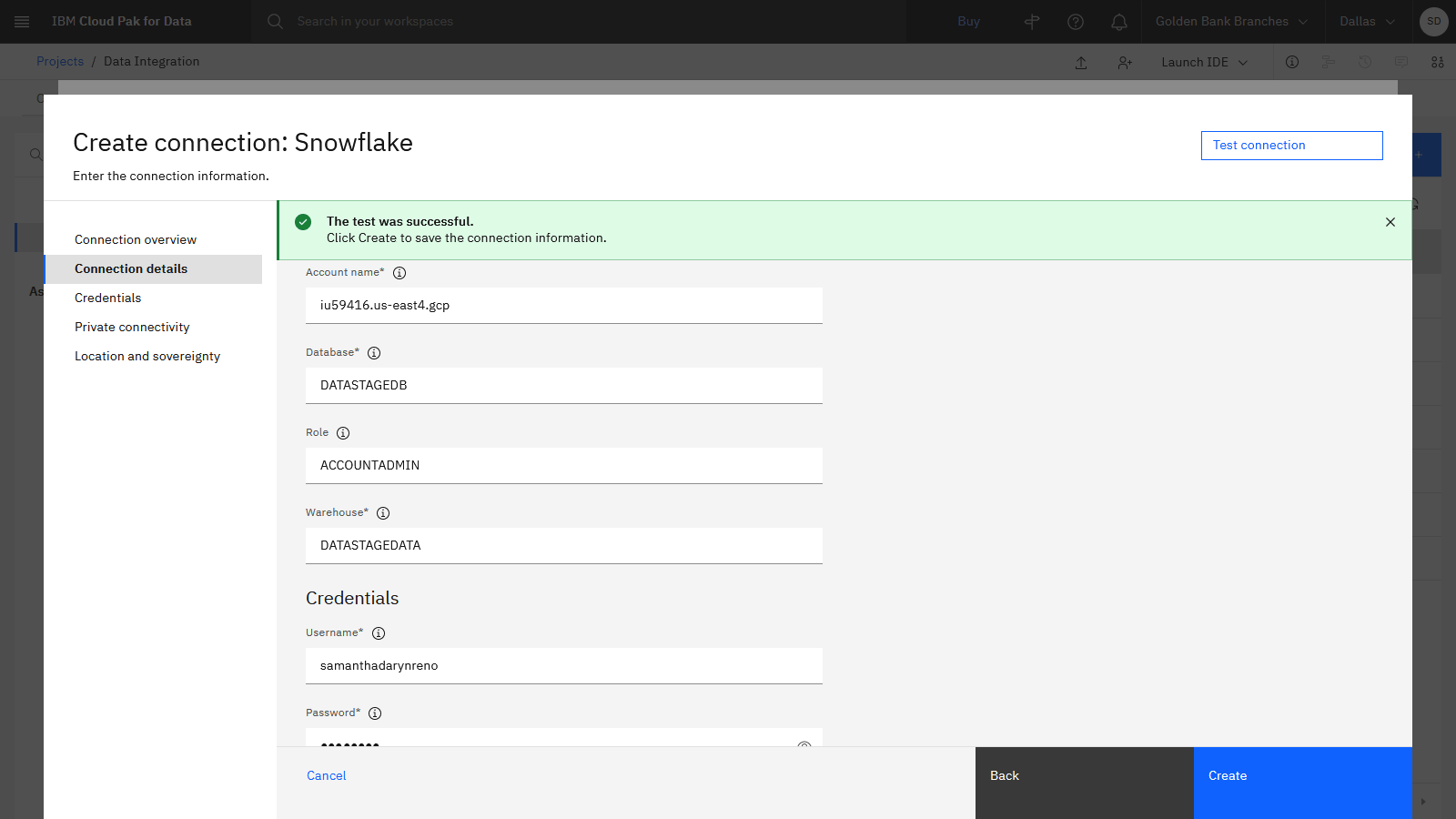
Task 4: Create a DataStage flow
To preview this task, watch the video beginning at 03:20.
Now you are ready to create a DataStage asset in the project. Follow these steps to create the DataStage flow:
-
From the Assets tab, click New asset > Transform and integrate data.
-
For the Name, type:
-
Click Create.
Check your progress
The following image shows the empty DataStage canvas. Now you are ready to design the DataStage flow.
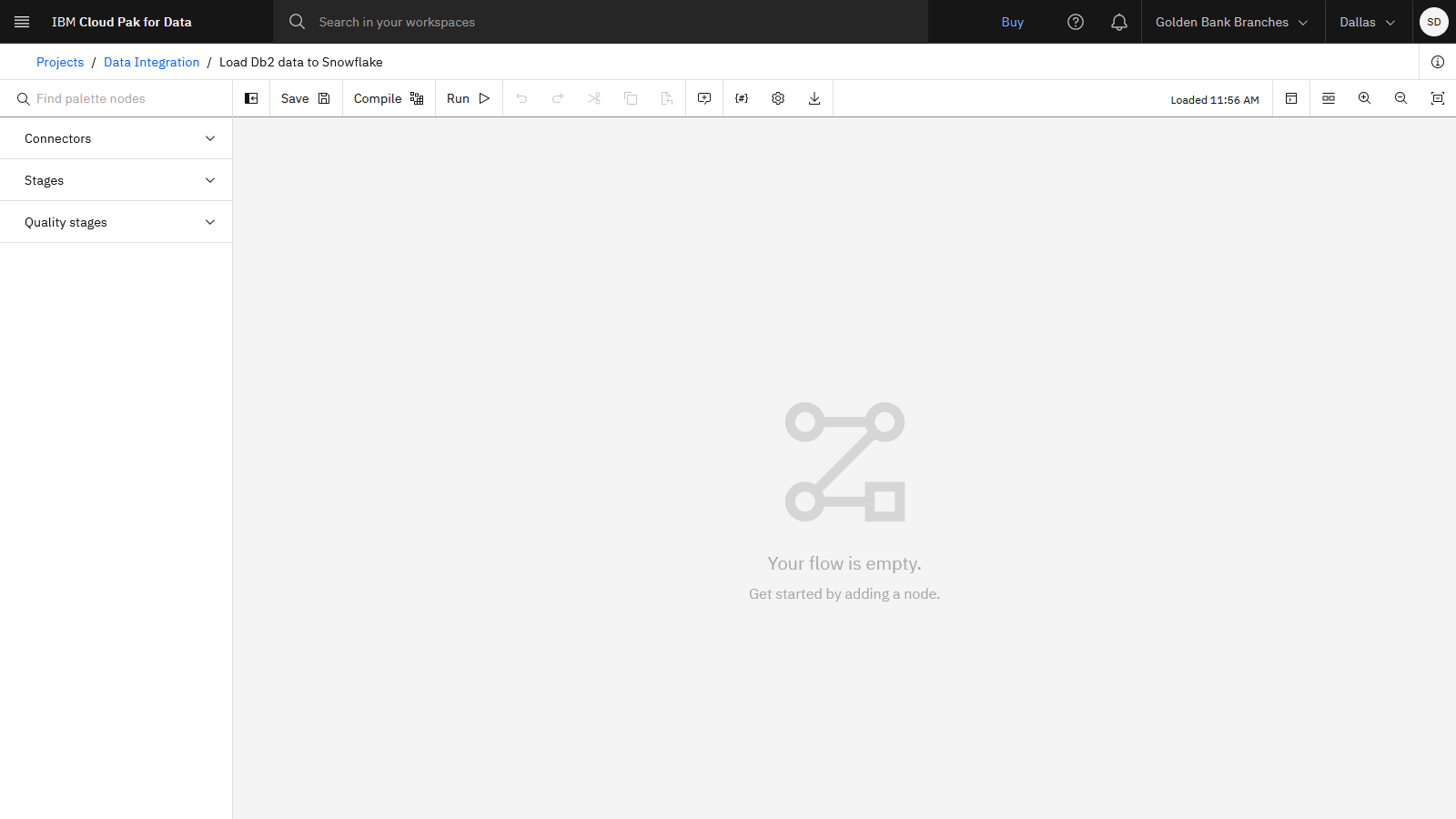
Task 5: Design the DataStage flow
The DataStage flow contains two connector nodes: the Db2 Warehouse connector pointing to the source data asset and the Snowflake connector pointing to the target data asset, and several other nodes to join and filter data assets. Follow these steps to add the nodes to the canvas:
Add the two connector nodes
To preview this task, watch the video beginning at 03:36.
Follow these steps to add the two connector nodes to the canvas:
Add the Source connector node
-
In the node palette, expand the Connectors section.
-
Drag the Asset browser connector and drop it anywhere on the empty canvas.

-
When you drop the Asset Browser connector on the canvas, you are prompted to select the asset.
-
To locate the asset, select Connection > Data Fabric Trial - Db2 Warehouse > BANKING > MORTGAGE_APPLICATION.
Tip: To expand the connection and schema, click the connection or schema name instead of the checkbox. -
Click Add to drop the Db2 Warehouse data source onto the DataStage canvas.
-
Add the Target connector node
-
In the Node palette, expand the Connectors section.
-
Drag the Asset browser connector and drop it onto the canvas so it is positioned as the second node.

-
To locate the asset, select Connection > Snowflake > MORTGAGE.
Tip: Click the checkbox to select the MORTGAGE schema name. -
Click Add to drop the Snowflake connection onto the DataStage canvas.
-
-
To link the nodes together, hover over the Mortgage_Application_1 node until you see an arrow. Drag the arrow to the Snowflake connection to connect the two nodes.

Configure the source and target nodes
-
Double-click the MORTGAGE_APPLICATION node to see its settings.
-
Click the Output tab.
-
Check the Runtime column propagation option. DataStage is flexible about metadata. It can handle situations where the metadata is not fully defined. In this case, you select Runtime column propagation to ensure that if the DataStage job encounters extra columns that are not defined in the metadata when the job actually runs, it adopts these extra columns and propagates them through the rest of the job. This feature allows your flow design to be flexible for schema drift.
-
Click Save.
Because you are reading data from Db2 Warehouse into Snowflake, the Db2 Warehouse connector is positioned first in the flow. Your goal is to load the Db2 Warehouse data into Snowflake. Next, you add a Snowflake connector that reads the data from the Db2 Warehouse connector. Thus, the Snowflake connector is positioned second in the flow.
-
-
Double-click the MORTGAGE_DATA connector to see its settings.
-
Change the node name to
-
In the settings side panel, click the Input tab.
-
Expand the Usage section.
-
For Write mode, select Insert.
-
For the Table name, add
after the schema name, so the full table name readsMORTGAGE.APPLICATION -
For the Table action, select Create. This setting creates the table in the specified database and schema in Snowflake, and then loads the enterprise data into that table.
-
Accept the default values for all other fields in the Actions section.
-
Click Save to update the changes, and return to the DataStage flow.
-
Add the nodes to join and filter data
To preview this task, watch the video beginning at 05:40.
Now you have a basic DataStage flow to load the data into Snowflake. Follow these steps to add several nodes to join and filter data:
Add another Asset connector node
-
In the node palette, expand the Connectors section.
-
Drag the Asset browser connector on to the canvas close to the MORTGAGE_APPLICATION node.
-
When you drop the Asset Browser connector on the canvas, you are prompted to select the asset.
-
To locate the asset, select Connection > Data Fabric Trial - Db2 Warehouse > BANKING > MORTGAGE_APPLICANT.
Tip: To expand the connection and schema, click the connection or schema name instead of the checkbox. -
Click Add to drop the Db2 Warehouse data source onto the DataStage canvas.
-
Add the Join stage node
-
In the Node palette, expand the Stages section.
-
In the Node palette, drag the Join stage on to the canvas, and drop the node on the link line between the MORTGAGE_APPLICATION and Snowflake_mortgage_data nodes. This action maintains links from the MORTGAGE_APPLICATION node to the JOIN node to the Snowflake_mortgage_data node.
-
Hover over the MORTGAGE_APPLICANT connector to see the arrow. Connect the arrow to the Join stage.
-
Double-click the MORTGAGE_APPLICANT node to see its settings.
-
Click the Output tab.
-
Check the Runtime column propagation option. As mentioned previously, this option accommodates schema drift.
-
Click Save.
-
-
Double-click the Join_1 node to edit the settings.
-
Expand the Properties section.
-
Click Add key.
-
Click Add key again.
-
Select ID from the list of possible keys.
-
Click Apply.
-
Click Apply and return to return to the Join_1 node settings.
-
-
Change the Join_1 node name to
. -
Click the Output tab.
-
Check the Runtime column propagation option to accommodate schema drift.
-
Click Save to save the Join_on_ID node settings.
-
Add the Filter stage node
-
In the Node palette, in the Stages section, drag the Filter node to the canvas, and drop the node on the link line between the Join_on_ID and Snowflake_mortgage_data nodes.
-
Double-click the Filter_1 node to edit the settings.
-
Expand the Properties section.
-
Under Predicates, click Edit.
-
Click the Edit icon
 in the Where clause column, and type
in the Where clause column, and type . This clause filters mortgage applications to only California applicants. -
Click Apply and return.
-
-
Click the Output tab.
- Check the Runtime column propagation option to accommodate schema drift.
-
Click Save to save the Filter node settings.
-
Check your progress
The following image shows the completed DataStage flow. Now you are ready to run the DataStage job.
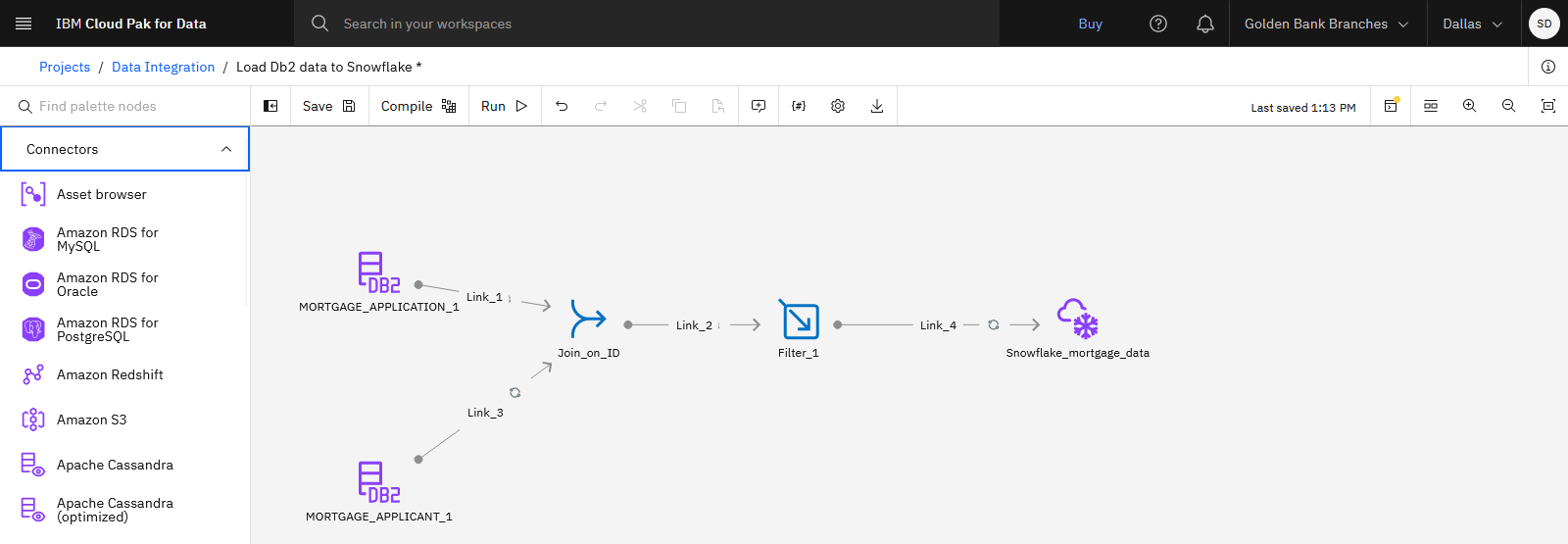
Task 6: Run the DataStage job
To preview this task, watch the video beginning at 07:23.
Now you are ready to compile and run the DataStage job to load the Mortgage Application data from Db2 Warehouse into Snowflake. Follow these steps to run the DataStage job:
-
On the toolbar, click Compile. This action validates your DataStage flow.
-
When the flow compiles successfully, click Run on the toolbar to start the DataStage job. The run might take a few minutes to complete.
-
When the run completes, you see a message stating Run successful with warnings.
Check your progress
The following image shows the successful run completed. Now that the DataStage job completed successfully, you can view the new table in Snowflake.
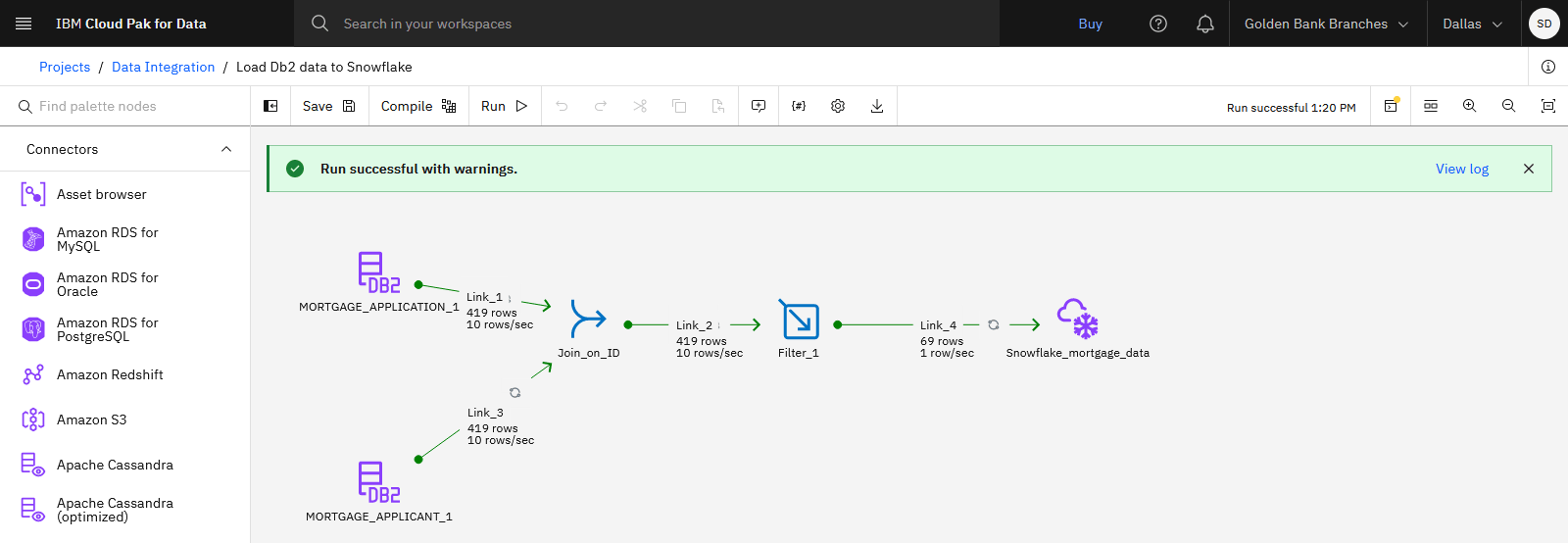
Task 7: View the data asset in the Snowflake data warehouse
To preview this task, watch the video beginning at 07:31.
To check whether the data was loaded data into Snowflake correctly, you can go back to your Snowflake dashboard.
-
Navigate to Data > Databases.
-
Expand DATASTAGEDB > MORTGAGE > TABLES.
-
Select the APPLICATION table.
-
Under the table name, click the Data Preview tab.
-
Select the DATASTAGEDATA warehouse.
-
Click Preview to see a preview of the Mortgage Application data imported from DataStage.
Check your progress
The following image shows the loaded table in Snowflake.
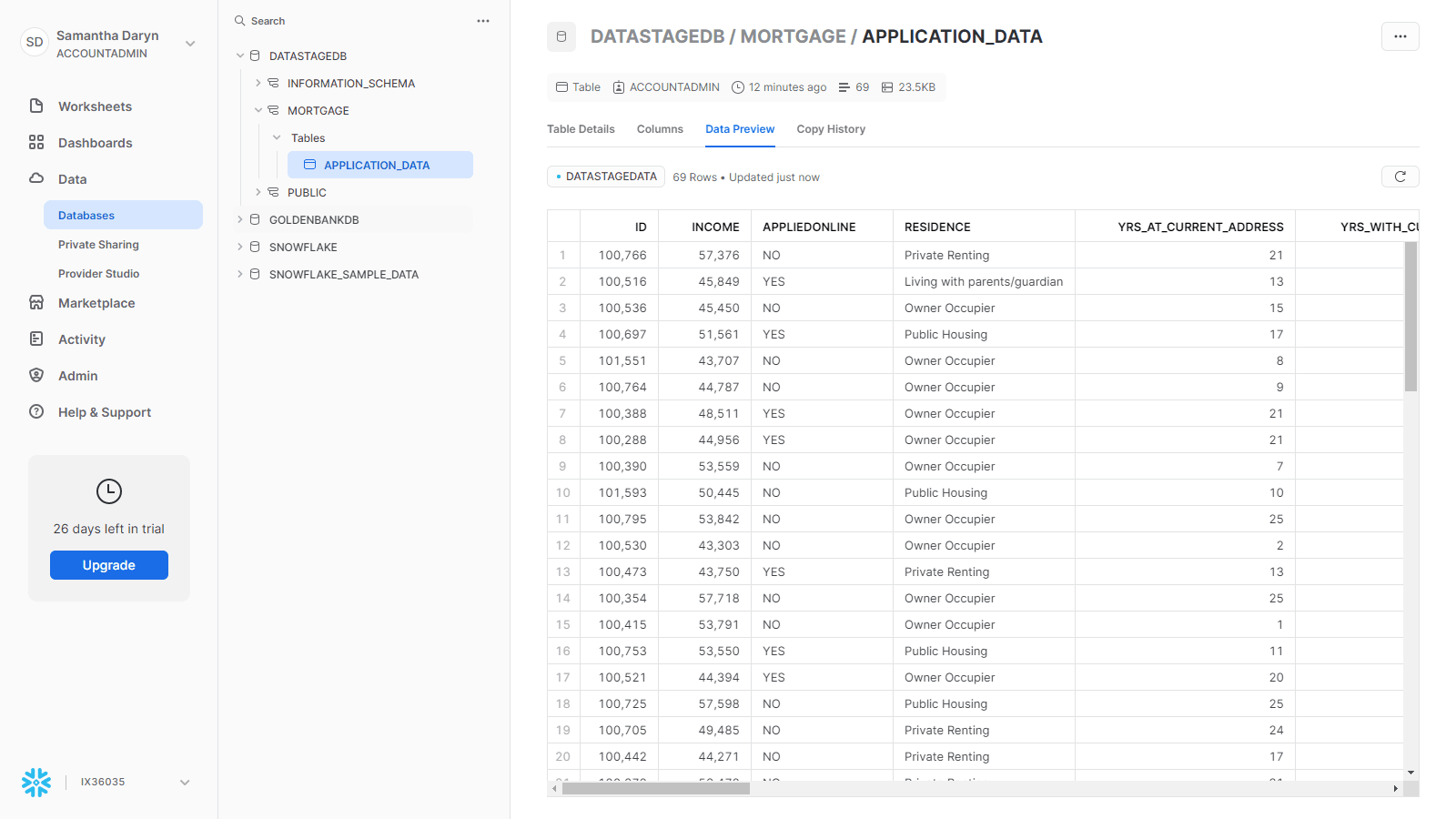
You successfully loaded enterprise data from a Db2 Warehouse into Snowflake by using DataStage.
Next steps
Try other tutorials:
Learn more
-
View more videos
Was the topic helpful?
0/1000