Evaluation Studio for Agentic AI applications
You can use Evaluation Studio to compare evaluations of an AI application.
Consider the following scenario:
- You build an agentic AI application tailored to your use case.
- You evaluate the application using a defined set of test data.
- Based on the output, you identify areas for improvement and make changes to the application.
- You re-run the evaluation to see how the changes affect the results.
- You repeat steps 2-4 multiple times as part of the iterative development process.
Now you want to compare the results of the evaluations to identify the version of the application that performs best according to key criteria.
Evaluation Studio for Agentic AI Applications helps you to streamline this process by enabling you to:
- Track and manage multiple evaluation runs.
- Visualize and compare metrics across iterations
- Identify the most effective version of your AI application based on evaluation outcomes.
Key terms
- AI experiment
- An asset type that stores evaluated metrics for different runs of a given Agentic AI application.
- AI experiment run
- An evaluation of an Agentic AI application with some test data.
- AI evaluation
- An asset type that is used to compare results of different experiment runs.
Requirements
You can compare AI assets in Evaluation Studio if you meet the following requirements:
Required roles
You must be assigned the Admin or Editor roles for your project in watsonx.governance to use Evaluation Studio. You may need to be assigned the Admin role for your instance. For more information on roles, see Managing users for the Watson OpenScale service in the IBM Software Hub documentation.
Service plans
Evaluation Studio is restricted to certain service plans and data centers. For details, see Regional availability for services and features.
Experiment tracking for an Agentic AI application
First, enable experiment tracking in the notebook that created the the Agentic AI application. (See the sample notebook )
Add the following code:
from ibm_watsonx_gov.entities.enums import Region
# Initialize the API client with credentials
api_client = APIClient(credentials=Credentials(api_key={APIKEY}, region=Region.AU_SYD.value))
# Create the instance of Agentic evaluator
evaluator = AgenticEvaluator(api_client=api_client, tracing_configuration=TracingConfiguration(project_id={project_id}))
ai_experiment_id = evaluator.track_experiment(
name="AI experiment for Agentic application",
use_existing=True
The use_existing flag enables you to use an AI experiment that already exists and has the same name.
Next, trigger an experiment run to evaluate the application by using the following code:
name = "run_1"
description = "Experiment run 1"
custom_tags = [
{
"key": "entity",
"value": "Finance"
},
{
"key": "output",
"value": "unstructured text"
},
{
"key": "use_case",
"value": "Banking"
},
]
run_request = AIExperimentRunRequest(
name=name,
description=description,
custom_tags=custom_tags
)
run_details = evaluator.start_run(run_request)
# Invoke the application
result = app.batch(inputs=question_bank_df.to_dict("records"))
evaluator.end_run()
result = evaluator.get_result()
When you start an experiment run, you can provide a name, description, and custom tags to capture additional context about the evaluation.
When the experiment run is created, the application is run with the test data. You can invoke the application multiple times within the same experiment run.
When the experiment run is complete, the end_run method computes the metrics that you configured at the application level and node levels. The metrics are stored against the run.
You can analyze the results for an experiment run, make some changes in the application, and re-evaluate it by triggering a new experiment run.
Comparing Experiment runs by using Evaluation Studio
You can compare the results of various runs by using Evaluation Studio. You can create the AI Evaluation asset either from the UI or from a notebook.
From the UI
-
Go to Project->Asset, and then click Evaluate and compare AI assets.
-
Click AI experiment.
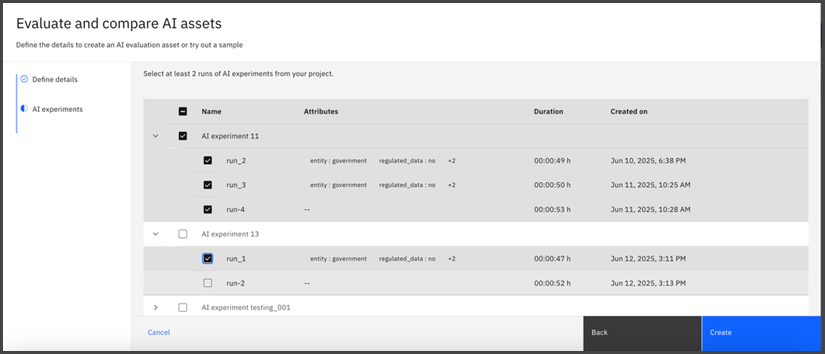
- Select the experiment runs that you want to compare, and then click Create.
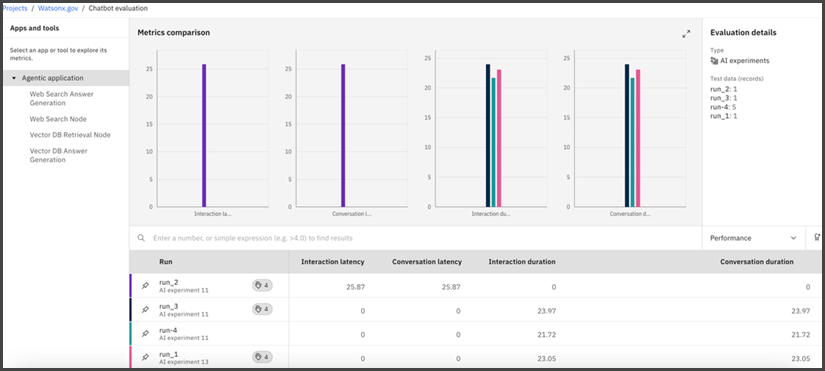
A chart shows how the metrics compare for the experiment runs.
From a notebook
You can use the following code to compare experiment runs:
# Compare all the runs of given AI experiment
ai_experiment = AIExperiment(
asset_id = ai_experiment_id
)
ai_evaluation_name = "AI evaluation to compare Banking experiments"
evaluator.compare_ai_experiments(
ai_experiments = [ai_experiment],
ai_evaluation_details = AIEvaluationAsset(name=ai_evaluation_name)
)
You can also compare experiment runs that belong to different AI experiment assets.
# Select all runs from 1st experiment for comparison
ai_experiment1 = AIExperiment(
asset_id = ai_experiment_id
)
# Select specific runs from 2nd experiment for comparison
ai_experiment2 = AIExperiment(
asset_id = ai_experiment_id_1,
runs = [<Run1 details>, <Run2 details>] # Run details are returned by the start_run method
)
evaluator.compare_ai_experiments(
ai_experiments = [ai_experiment1, ai_experiment2]
)
The output of this method is a link to the Evaluation Studio UI where you can visualize and compare the metrics for the experiment runs you selected.
Analyzing the results and configuring experiment runs in AI evaluations
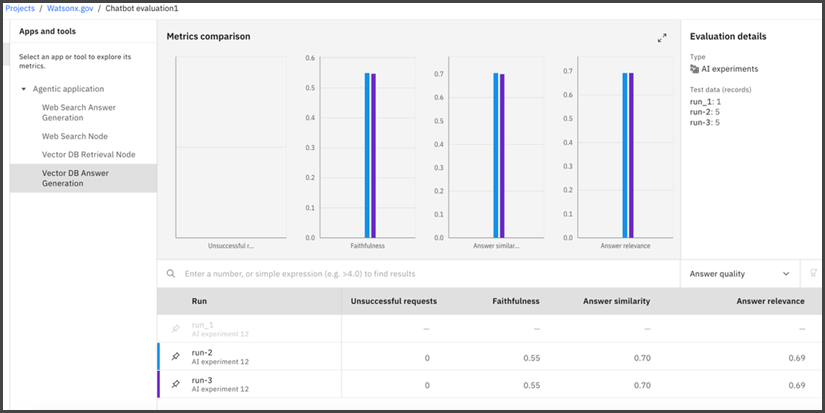
The left panel shows the Agentic application and a list of the tools (nodes) that it uses.
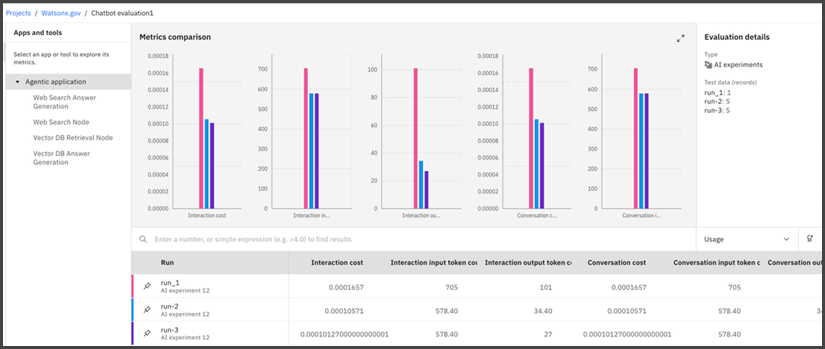
By default, the results show the application level metrics, such as interaction cost, latency, and so on.
To view metrics for a specific node, click the node name in the left panel. Metrics for that node across all the runs are displayed. If the node was not evaluated in some of the runs, the table shows empty rows for those runs.
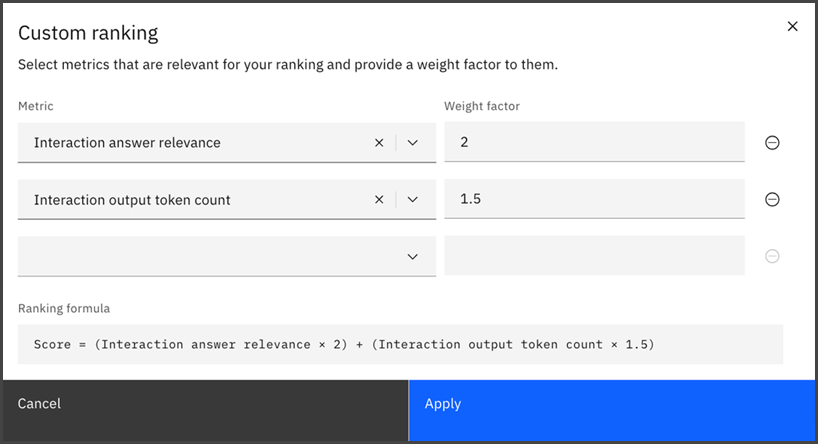
To assign weights to specific metrics and rank the runs based on the scores for the selected metrics, use the Custom ranking option.
To show or hide experiment runs from the result chart and table, click Edit Assets  .
.
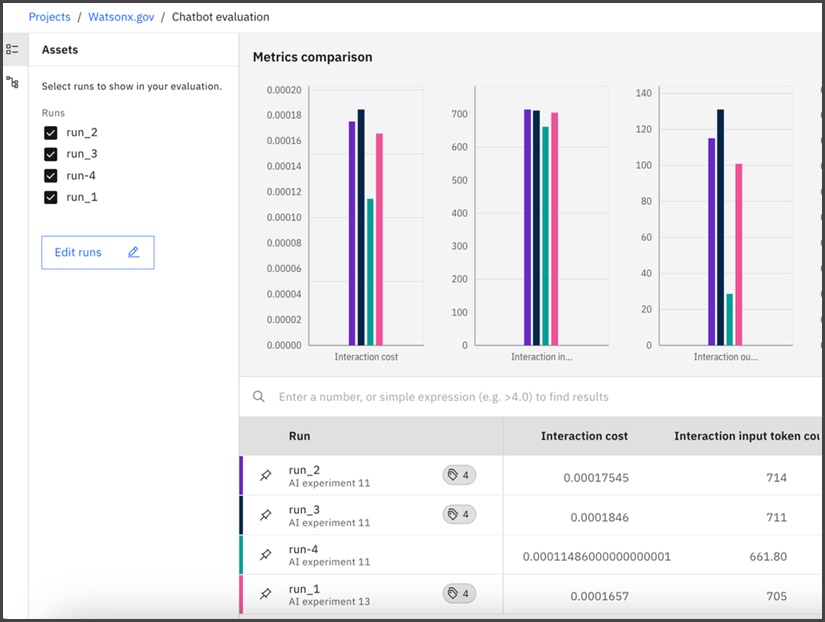
To add or remove experiment runs from the AI evaluation assett, click Edit runs.
