Evaluating generative AI output in multiple languages
Last updated: Jul 04, 2025
You can now evaluate generative AI output in multiple languages by using the Generative AI Quality monitor in watsonx.governance. You can select the language for which you want to compute quality metrics when you configure your evaluation.
To run multilingual evaluations:
-
At runtime using the API or SDK, see the runtime multilingual support notebook.
-
At design time using the SDK or with a custom tokenizer, see the design-time multilingual support notebook.
Supported languages
- Arabic (ar)
- Danish (da)
- English (en)
- French (fr)
- German (de)
- Italian (it)
- Japanese (ja)
- Korean (ko)
- Portuguese (pt)
- Spanish (es)
Note: Note: For the most accurate results, use the same language for the prompt instructions, input data, and generated output. If different languages are used, the evaluation metrics are still computed, but the
results might be less reliable.
Supported metrics by task type
- Summarization
- ROUGE Score
- Cosine Similarity
- Jaccard Similarity
- Normalized Precision
- Normalized Recall
- Normalized F1 Score
- SARI
- METEOR
- HAP Score
- PII Detection
- Generation
- ROUGE Score
- Normalized Precision
- Normalized Recall
- Normalized F1 Score
- METEOR
- HAP Score
- PII Detection
- Extraction
- Exact Match
- ROUGE Score
- Question Answering (QA)
- Exact Match
- ROUGE Score
- HAP Score
- PII Detection
- Retrieval-Augmented Generation (RAG)
- ROUGE Score
- Exact Match
- HAP Score
- PII Detection
Running evaluations from the user interface
- Create a project: Select New Asset and create a new Prompt Template Asset in the project, then select Chat and build prompts with foundation models with Prompt Lab.
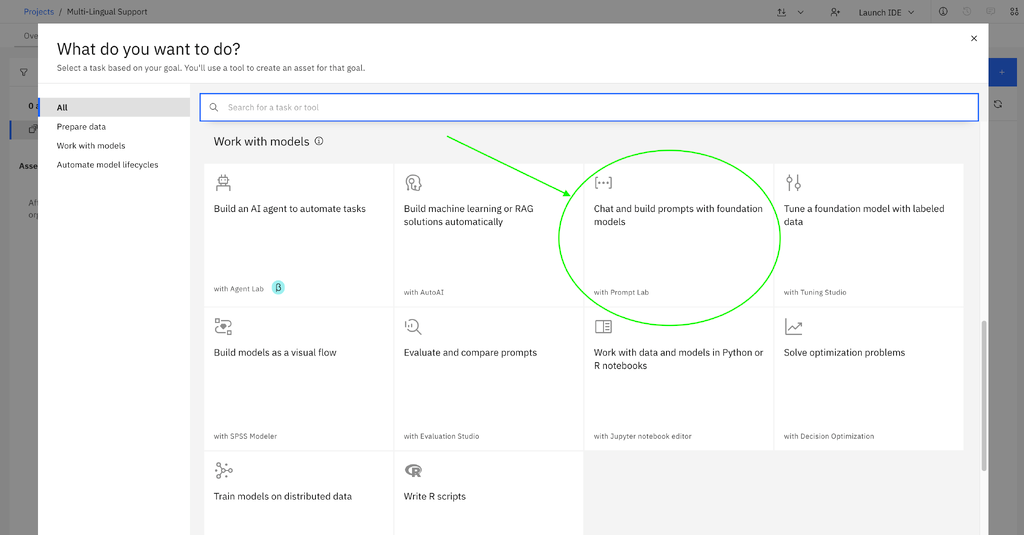
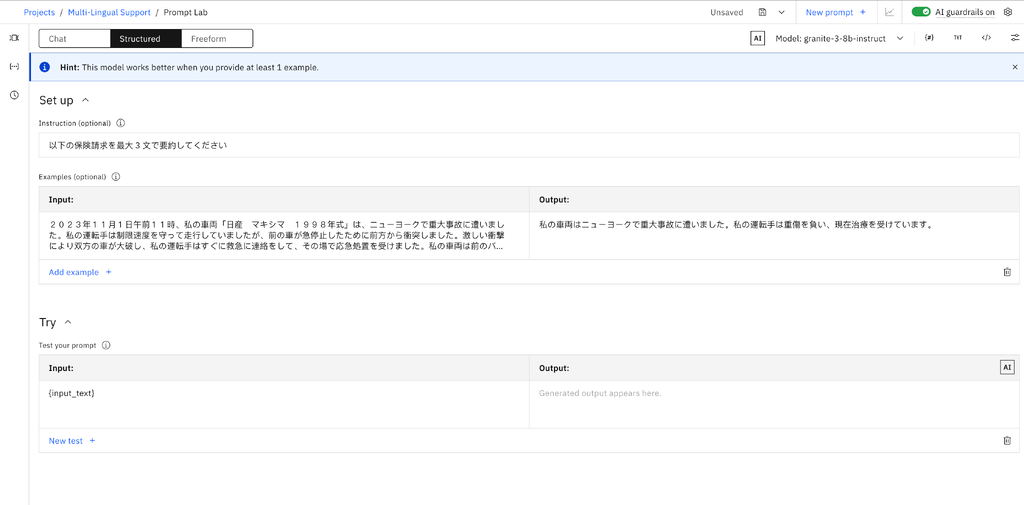
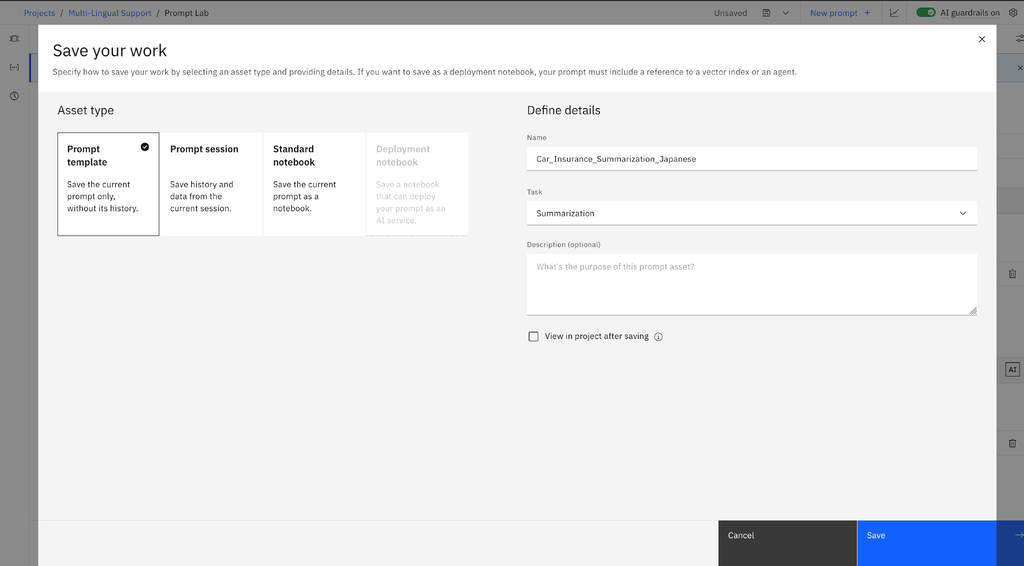
- Create and save your Prompt Template Asset with the data in the language in which you want to evaluate the prompt. Add your input variables and a sample input.
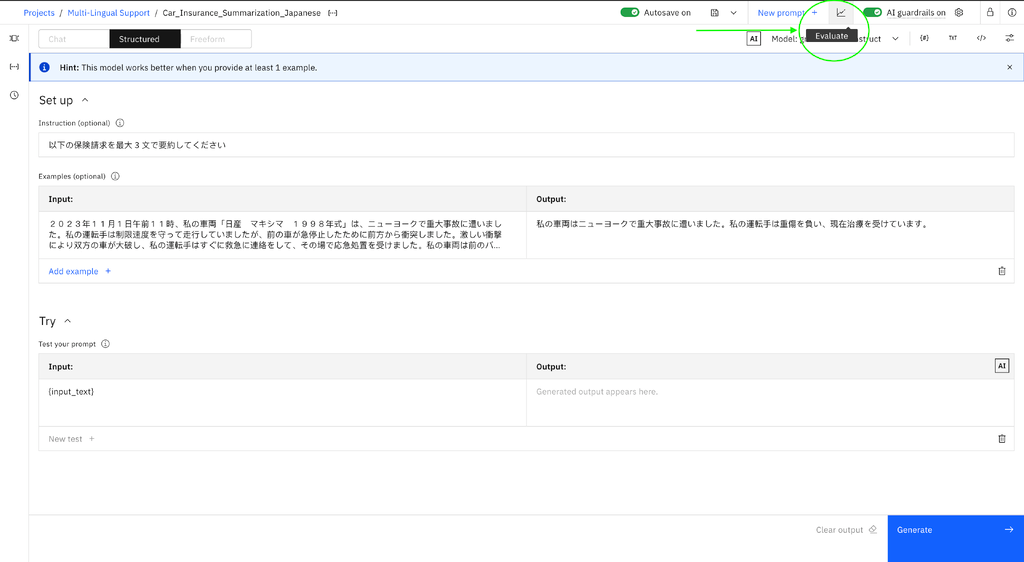
- Below is an example for a Japanese car insurance with the claim summarization prompt template.
- Save the Prompt Template Asset with the correct task type.
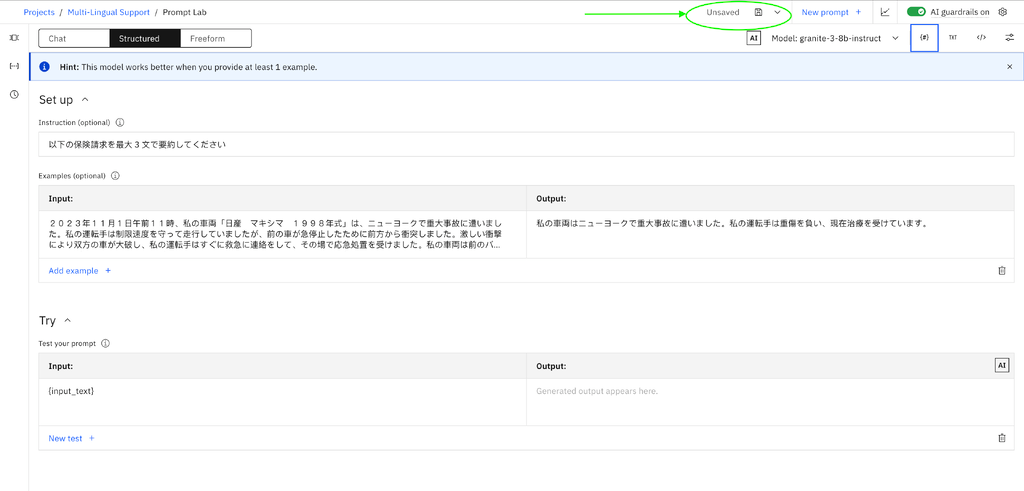
- You can start an evaluation by selecting the Evaluate button from the Prompt Lab page.
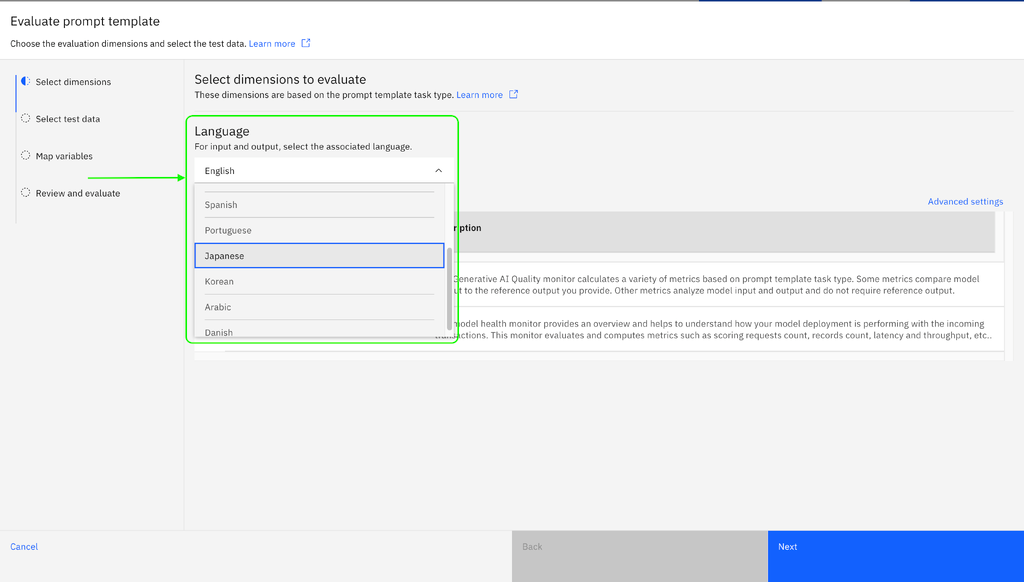
- Select the language for which you want to evaluate the metrics then click Next.
- After you select a lanaguage, you cannot change it. You must create a new Prompt Template Asset for another language.
- The metrics that are not supported are not available for evaluation in the UI.
- For production deployment spaces, the Drift monitor is only supported for English and is not available for other languages from the UI.
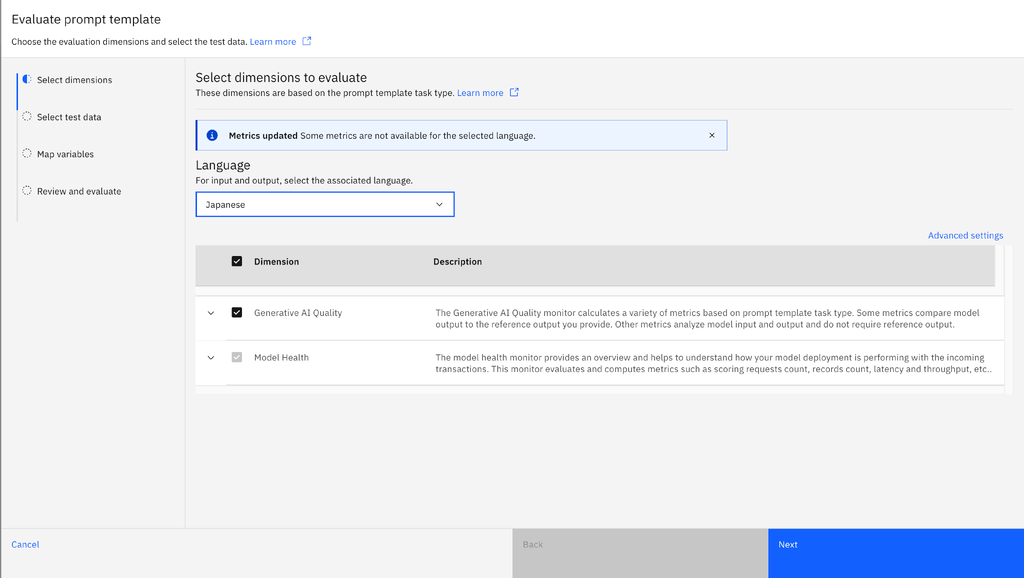
- Upload the test data set in the selected language and select the column mapping. Then, select Next to proceed to the Review and Evaluate section where you can verify the language that is selected.
Note: The language field can still be changed by going back to the Select Dimensions section.
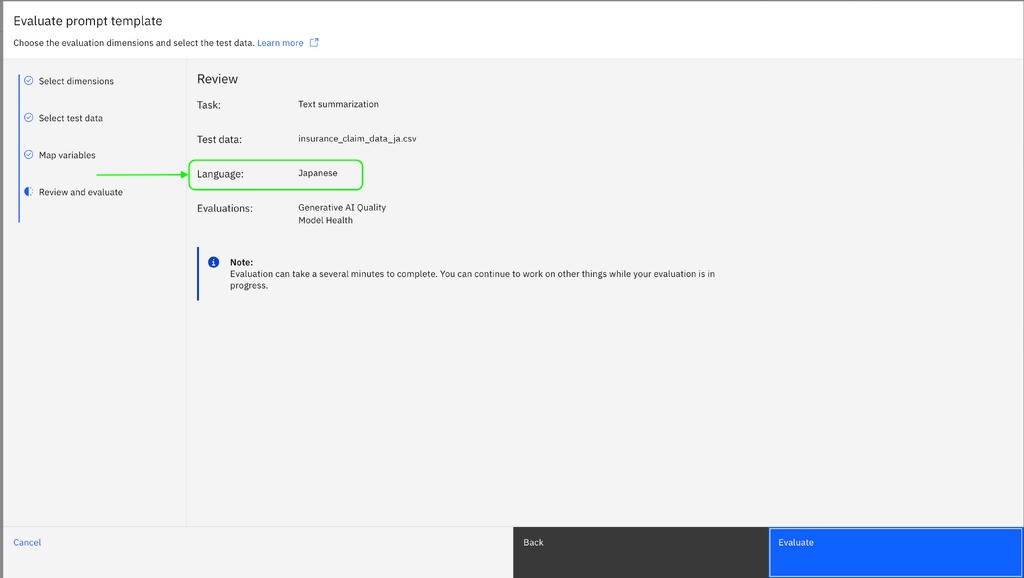
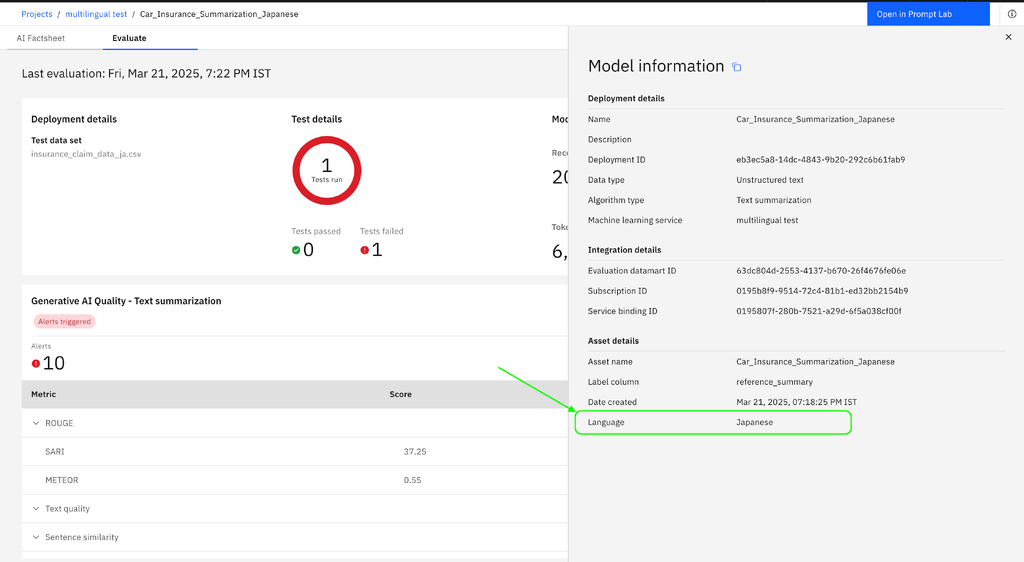
- Click on Evaluate to evaluate the chosen metrics more accurately for the selected language. You can also see the language selected in the Model Summary once the evaluation is complete.
Learn more
Parent topic: Evaluating AI models
Was the topic helpful?
0/1000